作者:Daniele Bagni
赛灵思公司DsP 专家
电子邮箱:Daniele.bagni@xilinx.com
Giulio Corradi
赛灵思公司IsM 高级系统架构师
电子邮箱:Giulio.corradi@xilinx.com
这种全新的赛灵思综合工具可将手动流程实现自动化,从而消除大量的设计错误来源,并加速开发周期中极为漫长且经常反复操作的部分的设计进程。
FPGA 技术是一种强大且高度灵活的PID 控制器实现方法。由于FPGA 器件拥有大量的并行资源,可为同步运算提供多个比例积分微分(PID)实例。此外,FPGA 还能够在不影响此前设计的其它PID 的性能的情况下,根据应用需求,灵活添加更多PID 环路。如果在新型赛灵思 Zynq™ -7000 All Programmable soC 的可编程逻辑(或架构)中实现PID,可以获得更多新的优势,因为功能强大的板上ARM® Cortex ™双A9 核处理系统可以直接利用FPGA 的功能。
但是,FPGA 器件一般要求使用VHDL 或Verilog 等寄存器传输级(RTL)设计语言,这可能与控制工程师的知识背景存在一定的差距,会妨碍FPGA 技术的使用。为消除这种差距,赛灵思新推出Vivado 高层次综合(HLs)设计工具。这种工具能够将C、C++ 或system C设计规范转换为RTL 实现方案,以便综合到赛灵思FPGA 中。这种转换只需要对常见的C 或C++ 代码稍作调整,因此不会造成严重的知识脱节。
另外,近年来电气驱动器和机器人也正在设法进军联网控制系统的范畴,这类联网系统在配备有通信信道的环路中使用PID。在这类应用中,FPGA 实现的确定性和速度占巨大优势。
但是由于还是需要与软件通信协议栈互动,系统架构师和控制工程师往往牺牲性能来换取全软件实现。庆幸的是,Vivado 提供了一种更简单、更通用的实现方法,可避开这种取舍。Vivado 只需通过把C或C++ 代码重新映射到Zynq-7000 All Programmable soC 器件的FPGA 架构上,就可以显著改善已开发出的联网控制系统的性能。
一种无所不在的器件
基本上所有自然和人为的控制系统均采用PID 或其变体PI(比例积分)或PD(比例微分)来反馈。大型工厂使用成千上万的PID 控制器来监控其化学或物理工艺。在汽车和运输系统中,PID 用于控制和保持发动机速度,确保平稳制动和控制众多转向功能;在电机中,PID 用于控制电机的电流和力矩;而在机器人中,PID 则用于驱动和稳定机器人的手臂或腿部的轨迹。PID 无处不在,就连医疗系统中也有其身影,例如用于控制I 类糖尿患者的人工胰腺,模仿天然胰岛素分泌特征。实际上生物系统自身也使用反馈来控制刺激反应,比如说视网膜系统适应光照的过程。
典型的反馈控制系统由设备(即待控制的机械或电气系统)和PID 控制器组成。数模(D/A)转换器将控制输出转换为适当的设备输入,而模数(A/D)转换器则将设备的输出转换为反馈信号。图1 是PID 工作原理图。简单地说,PID 控制器将负责处理传感器测出的设备输出值y(n) 和基准输入值w(n)之间的信息差e(n),也称为“误差”,然后对系统的激励器进行校正,以达到所需的命令输出值。PID 的每一个部分都对应一种特定的行为,或称为“模式”。P 行为根据误差的大小驱动控制器输出u(n)。I 行为消除稳态偏移,但可能会降低瞬态响应速度。D 行为负责评估趋势,预测输出校正,从而提高系统的稳定性,减少过冲并改善瞬态响应。
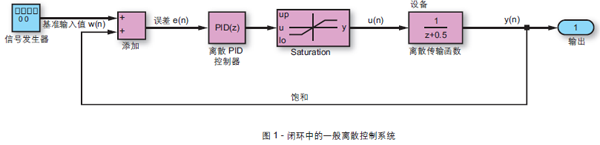
没有反馈控制的系统被称为开环,其传输函数(系统输入映射到输出的方式)的相移在单位增益下不得超过180°。开环的相位滞后度和单位增益下的相移(180°)之间的差异被称为“相位裕量”。系统增益和相移一般表达为拉普拉斯转换的模拟域s,或者Z 转换的离散域z。假定P(z) 和H(z) 分别为设备和PID 控制器的离散转换函数,则整个闭环系统的转换函数可表达为: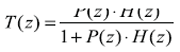
分式T(z) 的分子和分母中的z 的值分别称为零点和极点。PID 的相位滞后进入环路,会增加总的相位滞后。因此,一个高速的PID 应尽量降低这种滞后。在理想的情况下,PID 的响应时间应该是瞬间的,就像模拟控制器一样。因此PID 的计算速度尤为重要。在闭环系统中,必须确保稳定性,尤其是对机器人系统或电机驱动器这样的高端应用而言,更是如此。如果不稳定,控制环路的响应会发生寄生振荡,或是响应迟缓。稳定性可通过PID 控制器极点和零点的补偿来实现,从而让闭环系统尽可能实现最佳性能(增益和相位特性)。
在机器人和定位系统中,不管是单个PID 环路还是级联环路都存在一定的复杂性。例如,力矩由电流环路PID 控制,电机速度由与电流PID 级联的速率PID 控制,而位置则由与速度PID 级联的空间PID 控制。在这种情况下,用软件顺序执行每一个PID 环路的方法来降低总体计算延迟,效率会越来越低。
许多用于电力驱动器和机器人的PID 设计依赖浮点C、C++实现方案,这对控制工程师来说往往是最熟悉的表达方式。使用高速微处理器、微控制器或DsP 处理器就能够轻松地修改软件,无需花太多时间来设计更多硬件,直接就可以在软件中实现许多高难度的控制结构。
PID 控制器的基准模型
下面举一个实际案例来说明使用Vivado HLs 简化数字PID 控制器设计工作的优势。在这个设计案例中,我们考虑一个只有一个环路和一部直流电机的设备。因此转速是输出,电压是输入。
该设备可表达为等式1,用于表达拉普拉斯域的开环传输函数。这里略去了直流电机和转子的传输函数的详细微分计算: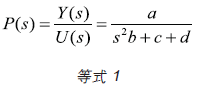
其中a、b、c、d 是设备的数值参数。等式2 是PID 控制器的传输函数。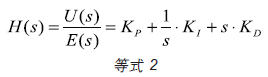
其中U(s) 和E(s) 分别是PID 输入和输出信号u(n) 和e(n) 的拉普拉斯转换。kp、kI 和kD 分别为比例级、积分级和微分级的增益。
梯形积分的Tustin 近似法就是将传输函数从拉普拉斯域转换到Z 域的方法之一。这样设备(等式1)和PID(等式2)的传输函数的数字化形式分别表达为等式3 和等式4:
其中TF 和Ts 分别为微分滤波时间和采样时间。图2 是由PID 控制器模块和设备组成的离散系统。
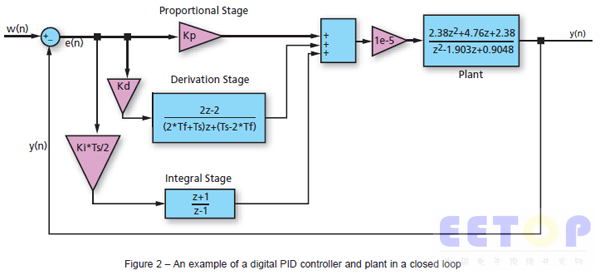
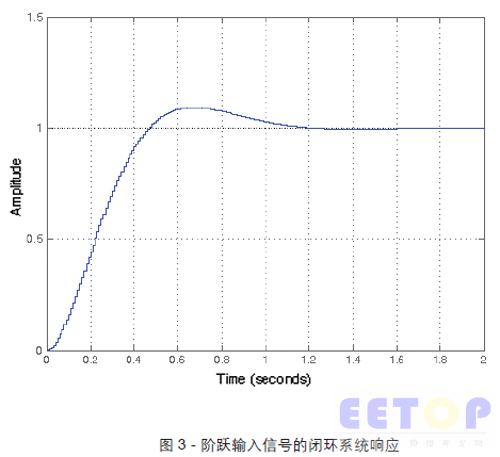
Mathworks 的控制系统工具箱MATLAB 和simulink 是一种设计和仿真模拟及数字PID 控制系统的强大工具。下列MATLAB 代码用于提供PID 控制器参数。图3 所示的是闭环系统对阶跃输入信号的响应,PID 参数设为kP=35.3675、kI=102.2398、kD=0.29161。
等式3 和等式4 可分别正式写成等式5 和等式6:

通过逆向转换等式5 和6,得到等式7 的公式,用于给离散时间域中的PID 控制器和设备模块建立模型, 如下列MATLAB 代码段所示:
w = ones(1, numel(t)); w(1:4) = 0;
C = (contr_d.Ts - 2*contr_d.Tf) / ...
(contr_d.Ts + 2*contr_d.Tf);
Gd = 2*contr_d.Kd / (contr_d.Ts + ...
2*contr_d.Tf);
Gi = contr_d.Ki * contr_d.Ts/2;
Gp = contr_d.Kp;
% closed loop
e_prev = 0; % e(n-1)
yi_prev = 0; % yi(n-1)
yd_prev = 0; % yd(n-1)
y_z1 = 0; % y(n-1)
y_z2 = 0; % y(n-2)
u_z1 = 0; % u(n-1)
u_z2 = 0; % u(n-2)
for i = 1 : numel(w)
% error
e(i) = w(i) - y_z1; % CLOSED LOOP
% derivation
yd(i) = -C*yd_prev + e(i) - e_prev;
yd_prev = yd(i);
% integration
yi(i) = yi_prev + e(i) + e_prev;
yi_prev = yi(i); e_prev = e(i);
% PID
u(i) = e(i) * Gp + Gd*yd(i) + Gi*yi(i);
% plant
y(i) = 1.903*y_z1 -0.9048*y_z2 + ...
1e-5*(2.38*u(i) + 4.76*u_z1 + ...
2.38*u_z2);
y_z2 = y_z1; y_z1 = y(i);
u_z2 = u_z1; u_z1 = u(i);
end
figure; plot(t, y, ‘g’); grid;
title ‘Closed Loop Step: plant+contr’;
使用VIVADO HLS 实现的PID 设计的性能
Vivado HLs 是最新一代赛灵思设计工具。它能够用C、C++ 和system C 编写的高级规范自动生成生产质量级RTL实现。换句话说,Vivado HLs 可实现手动流程的自动化,从而消除众多设计错误来源,并加速开发周期中极为漫长且经常反复操作的部分的设计进程。
Vivado HLs 在设计中采用了两种截然不同的综合方法。其中算法综合负责取出函数内容,在一定数量的时钟周期里,把功能描述综合到RTL 描述。而接口综合则负责把函数参数转换为有特定时序协议的RTL 端口,以便设计与系统中的其它设计通信。可以在全局变量、顶级函数参数和顶级函数返回值之上运行接口综合。
综合流程分步执行。第一步是抽取C 代码推断的控制与数据路径。接口综合会影响算法综合可实现的结果,反之亦然。与任何手动RTL 设计中得到的众多决策一样,结果将是大量可用的实现和优化以及数量更大的根据其相互影响关系得到的变体。Vivado HLs 让用户从这些细节中脱身,以最短的时间高效率地确定最佳设计。Vivado HLs 根据自身的默省设置,加上用户设定的约束和指令,迅速创建出最佳实现方案。
Vivado HLs 的核心流程是调度和捆绑。调度流程负责向特定时钟周期分配每一次运算。调度流程中制定的决策需要考虑时钟频率、时钟非确定性、器件技术库的时序信息以及面积、时延和吞吐量指令等诸多因素。捆绑是用于判断何种硬件资源或者内核用于每次调度操作的流程。例如,Vivado HLs 会自动判断是否同时使用加法器和减法器,或者是否单个加法减法器就能处理两次运算。因为捆绑流程制定的决策会影响运算的调度,比如用流水线化的乘法器代替标准的组合乘法器,因此,调度过程中应考虑捆绑决策。
Vivado HLs 通过如下方式可以加速验证和设计优化进程:
• 缩短以前的手动RTL 创建流程,并根据功能C 规范自动创建RTL,从而避免转换错误;
• 迅速方便地完成多种架构的评估,致力于打造出理想解决方案。
使用功能C 规范替代RTL 设计,加快仿真进程,尽早发现设计错误。
C 代码实现与MATLAB 模型极其相似,如下所示。假定在现实世界中,PID 输入和输出信号达到用户能控制的饱和度。PID 系数(等式7 的GI、GP、GD 和C)以及e(n) 和u(n) 信号的最大值和最小值假定在任何函数调用中都是顺序加载在PID 内核上的。假定两个输入和输出信号也是相同的情况。
void PID_Controller(bool ResetN, float
coeff[8], float din[2], float dout[2])
{
// local variables for I/O signals
float Gi, Gd, C, Gp, Y, W, E, U;
// previous PID states:
// Y1(n-1), X1(n-1), INT(n-1)
static float prev_X1, prev_Y1;
static float prev_INT;
// current local states:
// X1(n), X2(n)
float X1, X2, Y1, Y2, INT;
// local variables
float max_limE, max_limU;
float min_limE, min_limU;
float tmp, pid_mult, pid_addsub;
// get PID input coefficients
Gi = coeff[0]; Gd = coeff[1];
C = coeff[2]; Gp = coeff[3];
max_limE = coeff[4];
max_limU = coeff[5];
min_limE = coeff[6];
min_limU = coeff[7];
// get PID input signals
// effective input signal
W = din[0];
// closed loop signal
Y = din[1];
if (ResetN==0)
{
// reset INTegrator stage
prev_INT = 0;
// reset Derivative stage
prev_X1 = 0;
}
// compute error signal E = W - Y
pid_addsub = W - Y;
pid_addsub = (pid_addsub>max_limE) ?
max_limE : pid_addsub;
E = (pid_addsubmin_limE : pid_addsub;
// Derivation
// Y1(n) = -C * Y1(n-1) + X1(n) -
// X1(n-1) = X1 - (prev_X1+C*Y1)
X1 = Gd * E;
pid_mult = C * prev_Y1;
pid_addsub = pid_mult + prev_X1;
pid_addsub = X1 - pid_addsub;
// update Y1(n)
Y1 = pid_addsub;
// Integrator
// INT(n) = CLIP(X2(n) + INT(n-1))
// Y2(n) = INT(n-1) + INT(n)
X2 = Gi * E;
pid_addsub = prev_INT + X2;
pid_addsub=(pid_addsub>max_limE)?
max_limE : pid_addsub;
INT = (pid_addsubmin_limE : pid_addsub;
Y2 = INT + prev_INT;
// output signal U(n)
pid_mult = Gp * E;
pid_addsub = Y1 + Y2;
tmp = pid_addsub + pid_mult;
tmp = (tmp > max_limU) ?
max_limU : tmp;
U = (tmp < min_limU) ?
min_limU : tmp;
// PID effective
// output signal
dout[0] = U;
// test the PID error
// signal as output
dout[1] = E;
// update internal states
// for the next iteration
prev_X1 = X1;
prev_Y1 = Y1;
prev_INT= INT;
return;
}
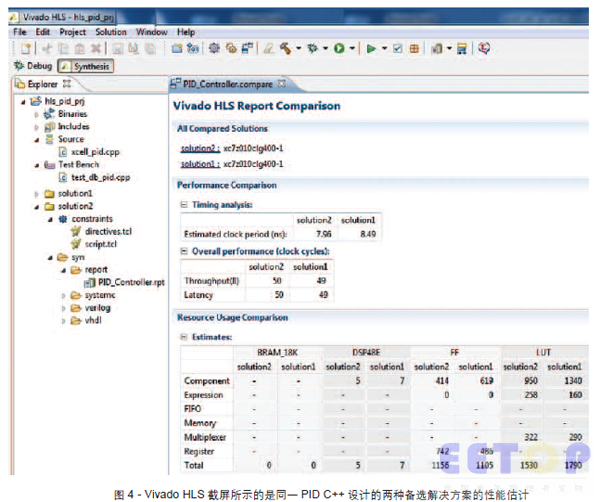
设定Zynq-7010 CLG400-1 器件的目标时钟周期为10 纳秒,PID 实现在该FPGA 的32 位浮点算术单元中。首次运行Vivado HLs(图4 中的“solution1”),估计的时钟周期为8.49纳秒,与FPGA 的118MHz 时钟频率对应。由于生成输出需要49 个时钟周期的时延,有效数据速率为2.4Msps。布局布线前估计FPGA 占用面积为7 个DsP48E slice,1,105 个触发器和1,790 个查找表。
通过分析Vivado HLs 生成的报告文件,发现工具生成了两个浮点加法减法器内核。因此采用下列指令:
set_directive_interface -mode ap_fifo
"PID_Controller" coeff
set_directive_interface -mode ap_fifo
"PID_Controller" din
set_directive_interface -mode ap_fifo
"PID_Controller" dout
set_directive_allocation -limit 1 -type
core "PID_Controller" fAddSub
set_directive_allocation -limit 1 -type
core "PID_Controller" fMul
前三条指令在自动生成的RTL 设计中设置待映射为FIFO的I/O 函数参数,而后两条指令将限制浮点乘法器和加法减法器数量,每个流程分配一个实例。
再次运行Vivado HLs(图4 中的“solution2”),估计的时钟周期为7.96 纳秒,与FPGA 的125MHz 时钟频率对应。对任何输出值, 有50 时钟周期的时延, 有效数据速率为2.5Msps。估计FPGA 占用面积为5 个DsP48E slice,1,156个触发器和1,530 个查找表,这就是最理想的结果。图4 的屏幕截图对这两种解决方案的Vivado HLs 综合估计报告进行了比较。
下面的RTL 代码段是Vivado HLs 自动为顶级函数生成的VHDL。工具生成的接口信号以clock reset(时钟复位)和start(启动) 为输入端口,以done(完成) 和idle(闲置)为输出端口。输入阵列din 和coeff 映射为输入FIFO 端口,故有empty 和read 信号。输出阵列dout 映射为输出FIFO 端口,故有其full 和write 信号。
— RTL generated by Vivado(TM) HLS - High-
— Level Synthesis from C, C++ and SystemC
— Version: 2012.2
— Copyright (C) 2012 Xilinx Inc. All
— rights reserved.
library IEEE;
use IEEE.std_logic_1164.all;
use IEEE.numeric_std.all;
library work;
use work.AESL_components.all;
entity PID_Controller is
port (
ap_clk : IN STD_LOGIC;
ap_rst : IN STD_LOGIC;
ap_start : IN STD_LOGIC;
ap_done : OUT STD_LOGIC;
ap_idle : OUT STD_LOGIC;
coeff_empty_n : IN STD_LOGIC;
coeff_read : OUT STD_LOGIC;
dout_full_n : IN STD_LOGIC;
dout_write : OUT STD_LOGIC;
din_empty_n : IN STD_LOGIC;
din_read : OUT STD_LOGIC;
ResetN : IN
STD_LOGIC_VECTOR ( 0 downto 0);
coeff_dout : IN
STD_LOGIC_VECTOR (31 downto 0);
din_dout : IN
STD_LOGIC_VECTOR (31 downto 0);
dout_din : OUT
STD_LOGIC_VECTOR (31 downto 0));
end;
三个工作日
可以从C 模型规范着手,利用有限的资源高效地将数字PID 控制器实现在赛灵思FPGA 器件中,甚至是在32 位浮点算术单元中。Vivado HLs 自动生成的RTL 占用面积极小,Zynq-7000 器件仅占用5 个DsP48E slice、1,156 个触发器和1,530 个LUT。FPGA 时钟频率为125MHz,有效数据速率为2.5Msps。仅三个工作日就得到这些设计结果,其中大部分时间用于构建MATLAB 和C 模型,而非运行Vivado HLs 工具本身。运行仅花了半天时间。
与其他备选方法相比,这种方法具有明显的优势。尤其是Vivado HLs 负责将浮点PID 直接映射到架构中。这样可以避免手动实现映射所需的中间步骤,从而改善项目的可移植性和一致性,与一般需要三个工作日以上的手动转换相比,大幅度缩短总开发时间。

本视频基于Xilinx公司的Artix-7FPGA器件以及各种丰富的入门和进阶外设,提供了一些典型的工程实例,帮助读者从FPGA基础知识、逻辑设计概念

本课程为“从零开始大战FPGA”系列课程的基础篇。课程通俗易懂、逻辑性强、示例丰富,课程中尤其强调在设计过程中对“时序”和“逻辑”的把控,以及硬件描述语言与硬件电路相对应的“

课程中首先会给大家讲解在企业中一般数字电路从算法到流片这整个过程中会涉及到哪些流程,都分别使用什么工具,以及其中每个流程都分别做了
@2003-2020 中国电子顶级开发网





