作者:Steve Leibson 赛灵思公司 Xcell每日博客编辑
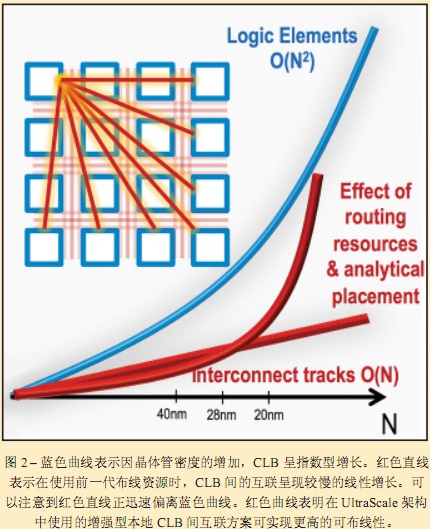
不久前发生在 ASIC 上的问题现又在 FPGA 上重演。到底是什么问题?那就是布线延迟对于设计性能的主导作用。多年以来,登纳德缩放比例定律(Dennard scaling)增加了晶体管速度,同时摩尔定律的扩展增加了每平方毫米的晶体管密度。糟糕的是对于互联来说其效果正好相反。电线因摩尔定律扩展而变得更细更扁,但速度却变得更慢。最终,晶体管延迟降低到无足轻重的程度,而布线延迟却成为主导。随着 FPGA 密度的增加以及赛灵思 UltraScale ™ All Programmable 器件进军 ASIC 级设计领域,相同的问题又出现了。UltraScale 器件经过重新设计后能够克服这种问题,但解决方案却并不方便简单。以下来介绍一下解决方案的各个步骤。
步骤1:压缩模块,以使信号无需传送太远。
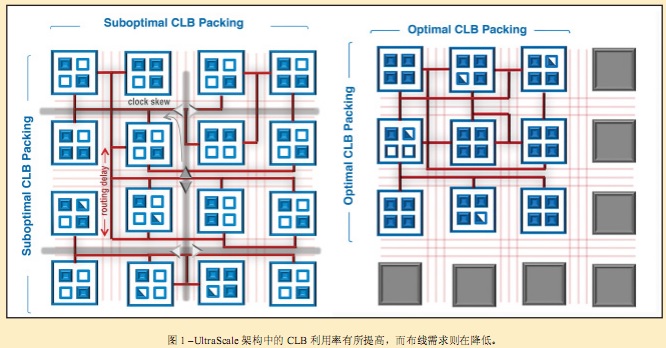
听起来很明确是不是?必要性是新发明的原动力,是时候在 UltraScale 密度方面采取行动了。UltraScale 架构中的CLB 已经过重新设计,这样 Vivado®设计套件就能更高效地将逻辑排列到 CLB 中。逻辑模块设计使排列变得更加紧密,因此 CLB 间的布线资源需求量就会变得更少。布线路径也变得更短。UltraScale 架构中 CLB 的变化包括 :为 CLB 中的每个触发器增加专用输入与输出(这样触发器就能单独使用从而实现更高利用率);添加更多触发器时钟使能 ;为 CLB 的移位寄存器和分布式 RAM 组件添加独立时钟。从概念上讲,改进后的 CLB 使用和排列情况如图 1 中的框图所示。

本视频基于Xilinx公司的Artix-7FPGA器件以及各种丰富的入门和进阶外设,提供了一些典型的工程实例,帮助读者从FPGA基础知识、逻辑设计概念

本课程为“从零开始大战FPGA”系列课程的基础篇。课程通俗易懂、逻辑性强、示例丰富,课程中尤其强调在设计过程中对“时序”和“逻辑”的把控,以及硬件描述语言与硬件电路相对应的“

课程中首先会给大家讲解在企业中一般数字电路从算法到流片这整个过程中会涉及到哪些流程,都分别使用什么工具,以及其中每个流程都分别做了
@2003-2020 中国电子顶级开发网





