作者:Csaba Rekeczky, Eutecus公司联合首席技术官兼副总裁, rcsaba@eutecus.com
Joe Mallett,赛灵思公司高级产品线经理, jmallett@xilinx.com
Akos Zarandy,Eutecus公司联合首席技术官兼副总裁, zarandy@eutecus.com
范围广泛的安全分析应用对处理带宽的要求迫使企业重新考虑系统硬件的设计方法。单个视频和图像DSP处理器已经不能以可接受的数据速率完成某些计算密集的分析运算了。此外,也没有强大可靠的解决方案能够在全视频帧速率下处理高分辨率(HD)。这也迫使系统工程师考虑多芯片或其它单芯片系统。两种解决方案各有其优点和缺点。
由多片DSP组成的多芯片系统一般可为设计人员提供更为熟悉的设计流程,但却增加了PCB成本、占用板级/系统级空间,同时还可能带来系统性能问题。另一方面,单芯片解决方案看起来在成本、封装和功耗方面具有优势,但可能会在无形中增加设计人员的学习难度,提高设计项目的复杂性和工程成本,并且有可能拖延产品发布的时间。
这也是位于加州伯克利的视频分析公司Eutecus在开发下一代安全分析产品—多核视频分析引擎(MVE™)时遇到的难题。
我们的第一代产品基于德州仪器(TI)的达芬奇(DaVinci)数字媒体片上系统(SoC)平台。 但在第二代产品中,我们需要更强大的处理能力和系统集成度。我们很快发现多个DSP器件的解决方案无论在成本上还是在系统一级效益都不高。我们需要一个能够方便地将上一代产品移植过来,并且能够为我们的第二代MVE提供更多特性的单芯片解决方案。
经过一番调研,我们找到了赛灵思公司的Sp a r t a n ®- 3A DSP 3400A。该器件提供了126个专用XtremeDSP®DSP48A 逻辑片,可以提供足够的性能来满足我们的系统要求,并且价格也很有吸引力。
当进一步了解到赛灵思嵌入式开发套件(EDK)支持Spartan-3A DSP之后,我们对设计移植方面的担心也很快消失了。赛灵思公司的EDK嵌入式开发套件可以实现基于赛灵思MicroBlaze®嵌入式处理器的双处理器硬件架构,与TI公司DaVinci平台双处理器硬件架构类似。
选定器件之后,开始将现有的基于DaVinci的代码移植到赛灵思双处理器嵌入式系统,以创造一个单芯片视频安全分析设计。然后,在FPGA构造中创建了适量的加速器模块来满足性能要求,其中包括在全帧速率下处理高分辨率视频。这就是第二代MVE系统,现在已经成功地销售到航空航天/国防、机器视觉和监控市场。
视频分析产品简介
多核视频分析引擎(MVE)基于InstantVision Embedded®软件和能够提供许多高级功能的专用C-MVA®协处理器。
MVE/C-MVA最新版本能够以全帧速率处理高分辨率视频。其功耗还不到1瓦,能够以全并行方式执行多种事件检测和分类算法。图1给出的是一个交通监控应用中视频分析输出的例子,针对不同类型的车辆、车流方向、车道变化以及违规变道等情况进行了分类,所有这些都是并发进行的并且利用不同的颜色进行了标记。
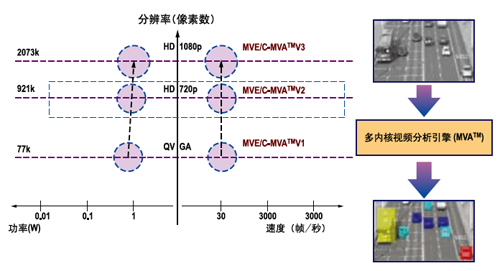
设计C-MVA协处理器的目标是能够扩展其运算的复杂度以支持密集物体空间的分析功能,此时需要重叠分析和处理不完整的对象/事件,因此特别具有挑战性。专用DSP在这方面的支持性很差,而且计算可扩展能力也不好。而FPGA在这两个方面则具有更大的灵活性。
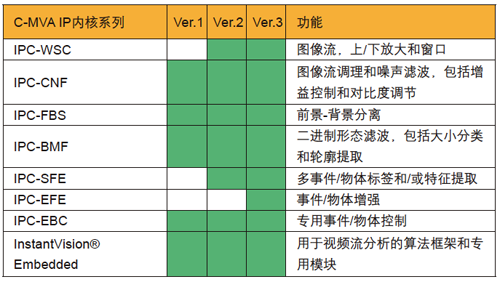
Spartan-3A DSP 3400A FPGA中的126个XtremeDSP DSP48A逻辑片能够提供高达30 GMAC的DSP性能,因此完全能够满足视频分析应用苛刻的成本和性能要求。赛灵思FPGA还允许我们根据客户需求增加更多视频分析功能以及相关的事件检测事例。我们在表1中做了小结。
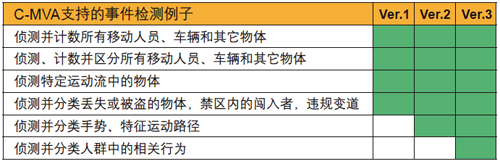
此外,通过赛灵思FPGA和ISE®设计套件工具,视频分析设计小组可以为终端客户定制解决方案方面提供更大灵活性。通过快速建立标准分辨率和高分辨率视频处理原型,我们可以快速定制视频分析引擎和片上系统(SoC)解决方案。这样我们就可以根据客户需求更高效地利用 Spartan-3A DSP 3400A或成本更低的Spartan-3A DSP 1800A FPGA器件中的可用资源。
FPGA解决方案另一个好处是可以利用同一硬件平台创建多种不同的衍生产品。由于我们已经使用VHDL设计了多种分析加速器引擎,因此可以将这些专用内核集成到C-MVA协处理器中。这种方法允许工程师重新利用双MicroBlaze嵌入式系统来创建不同的FPGA编程文件,这样就构成了高度可扩展的解决方案,可以轻松调节适应范围广泛的视频分析应用。
从DaVinci移植到赛灵思FPGA
我们先前一代的视频分析产品基于TI DaVinci数字媒体SoC芯片TMS320DM6446。该芯片包括ARM9x处理器和C64x+ DSP协处理器。在设计中,我们使用 ARM9x 做通信和控制,用 C64x+ 做分析算法的DSP处理。然而,两者组合起来构成的系统仍然无法满足我们第二代产品所需要的高性能处理要求。因此,我们转向了Spartan-3A DSP FPGA系列。
通过创建拥有两个独立运行MicroBlaze v7软内核处理器的赛灵思嵌入式系统,我们简化了设计移植任务。
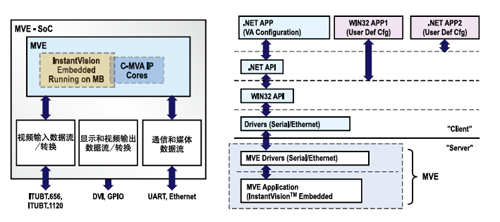
这种架构使我们可以分别移植ARM和DSP处理器代码,从而大大简化了设计移植过程。图2给出了Eutecus硬件系
统的框图,以及基于MVE的参考SoC设计。
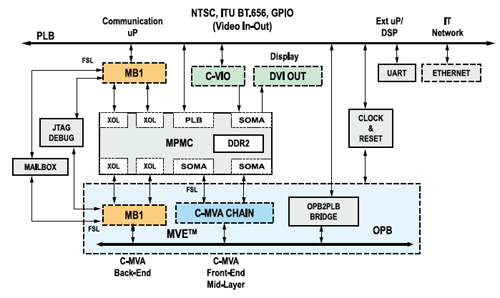
我们的MVE引擎包括运行在MicroBlaze (MB0) 上的InstantVision嵌入式软件,运行在 MicroBlaze (MB1) 上的系统控制和通信部分以及C-MVA协处理器。C-MVA协处理器是运行在FPGA构造上的硬件加速器IP内核模块链。
利用ISE设计套件和MicroBlaze软核,我们的ARM和DSP代码移植工作相当简单。一个突出优点就是,InstantVision跨平台环境是采用高级标准C/C++语言编写的,只需要很少的修改。
一旦完成代码移植,我们验证其功能的正确性并且识别出性能瓶颈。事实表明,优化和加速对原 TI 处理器开发的C/C++代码是一项重要挑战,因为当初在开发这一平台的过程中,我们在汇编级优化时使用了几个DaVinci C64x+协处理加速模块。在转换过程中,我们遵循以下一系列步骤:首先利用高级C函数来重写这些模块。最后,用运行在FPGA构造上的同等功能加速器模块来代替这些模块的大部分功能。
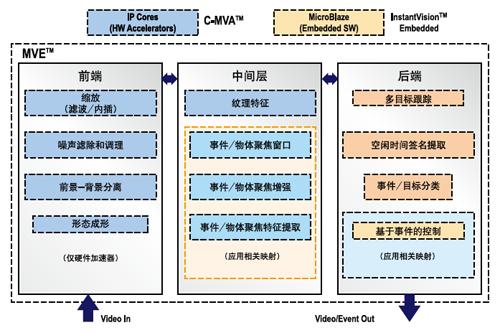
从功能的观点来看, MVE解决方案由三层组成,将接收标准/高分辨率视频流作为输入数据,然后生成事件检测元数据。生成的元数据提供目标/事件跟踪和分类支持,同时将一些用于调试目的的图像流也作为分析输出。我们的功能
模块要么通过运行在MicroBlaze处理器上的嵌入式软件实现,要么就以专用IP内核方式实现。我们将这些专用硬件
加速器置入FPGA构造,这些加速器构成的加速器链就组成了C-MVA分析协处理器。
如图3所示,MVE视频分析引擎的三个算法层包括几个主要的功能模块。利用FPGA中可用资源动态配置的专用IP内核可大大加速这些功能模块。C-MVA协处理器的设计基于这些IP内核,整个分析算法的前端和中层(参见图4)加速也是如此。我们可以利用赛灵思ISE设计套件支持的这种模块化设计方法同时在性能和功耗方面对系统进行扩展。
利用FPGA加速器模块增压
为真正发挥FPGA视频分析系统的全面潜力,我们需要将视频加速引擎集成到嵌入式系统中。 我们预见到几个性能瓶颈,因此设计小组开始采用VHDL进行一组加速器的早期开发。 作为赛灵思ISE设计套件和嵌入式开发套件 (EDK)的一部分,代码剖析器帮助我们进一步确定性能瓶颈并开发设计所需要的所有加速器模块。 表2提供了系列IP内核的全面列表。
与其他开发小组一样,我们的开发小组也分别由不同的硬件和软件开发人员组成。对于维持开发人员的生产力以保证项目的成功来说,在这两个设计领域之间保留足够的抽象非常关键。我们利用Xilinx Platform Studio中的Create
IP Wizard来改进这一任务,为硬件加速模块生成RTL模块和软件驱动文件。
这些模块包括访问寄存器所需要的接口逻辑、嵌入式系统中的DMA逻辑和FIFO。一旦利用模块创建了RTL,我们就将其放到嵌入IP目录中,设计人员可根据需求进一步修改。
我们的IP内核开发流程包括一个通用的标准外设模块开发流程,用于基于PLB46MPMC-OPB的回传。这些外设包括单端和多I/O原型 (SIMO,MIMO, MISO模型),支持我们为要求苛刻的图像流处理算法灵活创造多线程协处理器流水线。在设计和定制不同分析引擎的过程中,通过近乎任意次序对IP内核进行组合和配置,我们达到了这方面的要求。
MVE分析引擎由InstantVision嵌入式软件模块以及构成C-MVA分析协处理器的硬件加速器组成。我们在一片Xilinx Spartan-3A-DSP 3400A FPGA中实现了MVE的原型,并创建了SoC参考设计。其中包括所有通信和数据流所需要的I/O功能(参考图2了解完整的硬件固件框图)。 这一完整的SoC参考设计使用了91%的逻辑片资源、 81%的块RAM和32%的DSP逻辑片,不仅包含MVE分析引擎,还包括所有支持I/O模块。
单就MVE分析引擎来说(不包括MPMC-PLB主干和专用I/O组件),它仅使用了46%的逻辑片、44%的块RAM和23%的DSP逻辑片,因此可以将其移植到成本更低的Spartan3A-DSP 1800A FPGA器件。
在单个时钟周期内,我们设计的CMVA协处理器中所有IP内核可以完成所有相关处理。这一功能与异步FSL接口相结合,系统集成商能够利用来自系统其它部分的不同时钟域来驱动C-MVA协处理器。这样做可以让C-MVA在较低的像素时钟频率中运行,同时利用更高频率的内部系统时钟来驱动主干(backbone),从而在保证系统性能要求的同时大大降低功耗。
定制、封装和系统集成
为验证并进一步开发这一系统,我们创建了一个包括所有软件层在内的安全/监控应用,允许用户在系统的不同层面快速集成我们的产品。完整SoC设计在单个参考设计中包括硬件IP内核、固件和软件,请见图5。
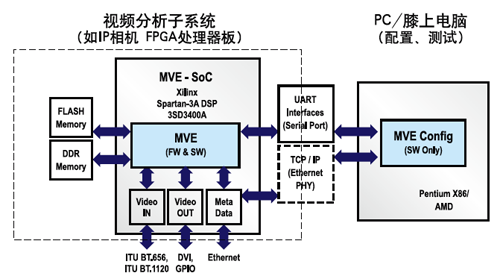
我们可在硬件、固件和软件组件等不同层次进行灵活定制以组成系统集成。服务器级的定制包括 PGA中的可定制SoC设计,而在客户(配置)一级,则可在WIN32或 Net API层进行修改。这种架构使我们及客户可快速实现不同配置和测试接口的原型。用户可以在UART或TCP/IP上实现客户-服务器 (C/S)通信,从而提供灵活的配置管理、性能精细调整、状态监控和固件升级。
尽管刚刚完成第二代产品,但我们已经开始考虑第三代产品的要求。根据在这一项目中取得的经验,我们在新一代产品中会着重考虑赛灵思的FPGA器件,特别是赛灵思公司正在致力于利用最先进的工艺技术推出更可靠更先进的新器件和DSP功能。

本视频基于Xilinx公司的Artix-7FPGA器件以及各种丰富的入门和进阶外设,提供了一些典型的工程实例,帮助读者从FPGA基础知识、逻辑设计概念

本课程为“从零开始大战FPGA”系列课程的基础篇。课程通俗易懂、逻辑性强、示例丰富,课程中尤其强调在设计过程中对“时序”和“逻辑”的把控,以及硬件描述语言与硬件电路相对应的“

课程中首先会给大家讲解在企业中一般数字电路从算法到流片这整个过程中会涉及到哪些流程,都分别使用什么工具,以及其中每个流程都分别做了
@2003-2020 中国电子顶级开发网





