数字图像稳定是图像序列处理中得一项重要的前处理步骤。早期的方法是对摄像机本身的机械和光路进行稳定,随着数字技术的发展,可以对采集到的图像进行处理,使图像在显示器上能够稳定地显示,同时也为了更好地为后续处理提供稳定的图像序列,如图像拼接、图像增强、信息融合、目标追踪、目标识别等各种图像处理技术的综合运用。在实现实时图像稳定系统方面,由于图像计算量大,必须选用高性能数字信号处理器。目前实现实时图像处理的主要方式有4种:1)基于通用PC机;2)基于通用DSP;3)基于专用或多DSP;4)基于可编程FPGA或DSP+FPG。在通用PC机上可方便地进行各种图像算法的仿真试验,但是这种方法只能在实验室进行,难以现场应用。其中基于通用DSP这种方案的优点在于,价格便宜、资料丰富、开发相对简单,并且处理速度也随着器件性能提高,已经能满足图像稳定所需要的实时处理,形成脱机系统。针对实时数字图像稳定处理,介绍一种采用高性能系列的DSP C6416,开发出一套数字图像处理系统。该系统采用双口RAM作为高速数据输入输出缓冲通道,由CPLD进行系统的逻辑控制,DSP的EDMA完成数据的片内片外传送,通过配置和软件优化,最终完成了系统的高度实时运行。
1 稳像方法和步骤
数字图像稳定处理过程主要由3部分组成:运动矢量估计模块(ME),运动矢量补偿模块(MC)和图像序列合成模块(IC)。通过ME模块找到帧间运动偏移,由MC模块进行图像拼接完成运动补偿,最后经IC模块进行图像剪裁输出。
运动矢量估计模块中,通过比较当前图像和参考图像中相同的部分,找到两帧图像问的偏移量,即运动矢量,广泛应用于视频处理与编码,如图1所示。
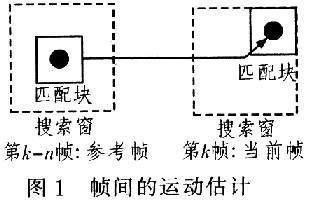
图1中用实线所画的方框表示匹配块,虚线所画的方框表示搜索窗。假定第k帧为当前帧,为了计算第k帧相对于第k-n帧的运动偏移量。在第k-n帧的中心位置选择一个N×N像素大小的匹配块,同时在第k帧上选择一个M×M(M>N)大小的搜索窗,搜索窗的中心位置与第k帧的匹配块中心位置重合,通过用式(1)比较两幅图像间所有相应像素间绝对差的累和VSAD(Sum of Absolute Difference),在搜索窗内找出和匹配块图像最匹配的位置,即VSAD最小值的位置。该匹配位置坐标和搜索窗中心点坐标的相对位置(△x,△y),即为两帧图像的偏移运动矢量。
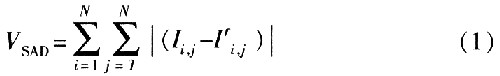
式中,![]() 分别为参考图像和当前图像(i,j)位置的像素强度。
分别为参考图像和当前图像(i,j)位置的像素强度。
获得的图像序列之间的运动矢量参数后,纠正当前图像,使其恢复到正确的位置,获得相对稳定的图像序列,然后送到相应的显示装置或存储介质。
2 稳像系统的方案设计
TMS320C6416是TI公司最新推出的高性能DSP,该器件拥有8个并行处理单元,工作频率为600 Hz,最高处理速度可达4800M/s(MFLOPS)。采用类似RISC的超常指令字(VLIW)结构,在最好的情况下,TMS320 C64X系列的DSP在一个指令周期可同时执行8条32位有效指令,因此可以达到极高的处理性能。
2.1 系统组成
为适合高速图像采集与处理,采用CPLD+DSP的应用方案,由于DSP只专注数据处理,但缺乏控制能力,利用高速逻辑器件CPLD配合DSP完成实时任务控制与处理,是系统的最佳组合。经过比较,选用XC95144XL作为CPLD控制器,主处理DSP TMS320C6416系列器件进行图像处理计算。该系统结构如图2所示。
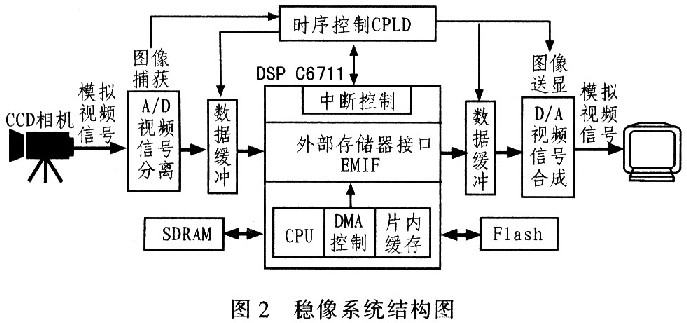
该系统输入输出都为标准模拟视频信号,设计采集图像大小为512×512像素,速度为30~60帧/s的实时采集。摄像头输入模拟视频信号后,经过SAA7110进行A/D转换和信号分离后,进入输入端高速数据缓冲区。输出端缓存中的数据,通过BT121进行D/A转换后,合成为标准模拟视频信号,可直接送监视器显示。用逻辑器件CPLD控制系统的工作时序。为适应高速数据吞吐,输入输出缓冲存储器选用了双端口RAM。
2.2 CPLD控制
系统的逻辑控制器是100引脚的XC95144,其主要工作是控制输入/输出帧存,以便DSP将存在其中的处理好的图像数据读出,并在同步控制信号和消隐信号的协同下形成标准视频输出信号,送到监视器显示。图3给出了逻辑控制的原理框图。
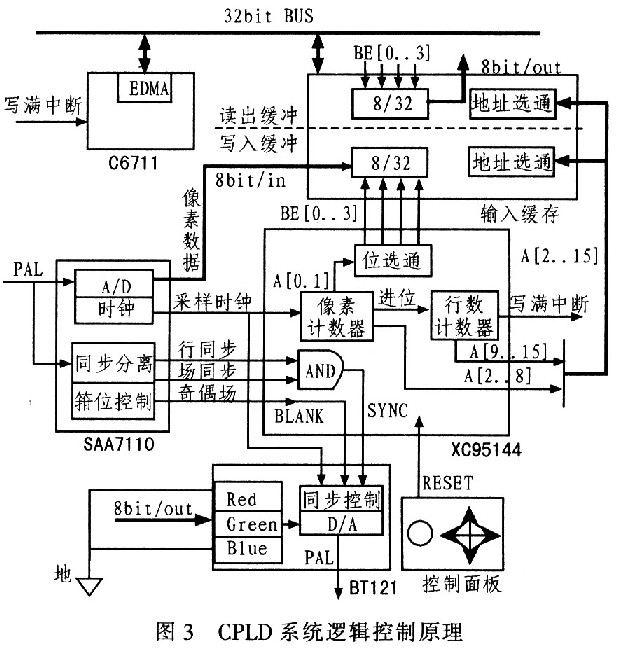
CPLD的逻辑控制的工作包括:1)根据SAA7110分离出的同步信号,经过逻辑判断后,给出BT121需要的同步信号;2)由于SAA7110输出的LLC2时钟与采样时钟、输出时钟是同步的,因而以LLC2作为采样数据存储和同步控制子系统的时钟,CPLD内部计数器进行数据采样计数,产生偏移地址,以控制输入/输出缓冲读写数据,使用LLC2时钟也避免了使用外部时钟需要解决的信号相互间的同步和锁相:3)计数器产生控制中断,通知DSP启动数据读/写EDMA通道和进行数据转移;4)低位地址A0和A1进行译码产生Bank Enable信号,送到双口RAM以进行数据位选通。由于输入/输出缓存具有对称的硬件结构,所以XC95144在进行地址计数时,产生两套相同Bank信号和地址偏移,供输入和输出双口RA-M。
3 数字图像数据的采集与输出
3.1 数据采集
系统的设计视频信号采集能力是从CCD获得模拟视频信号中采集到512×512大小的数字图像,并通过帧缓存——异步静态双端口存储器(dual-port RAM),经DSP的EDMA通道送到SDRAM中。采集模块的结构如图4所示。
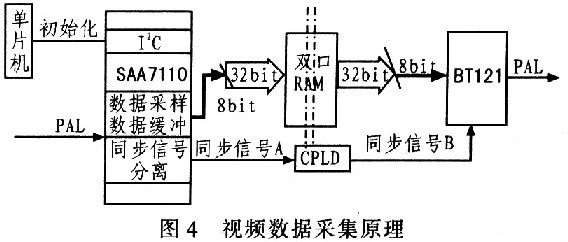
SAA7110的初始化通过I2C总线对其内部控制寄存器进行相应设置而实现,该系统将DSP上的McBSP(多通道缓冲串口)的两个引脚与SCL和SDA相连,将McBSP的引脚配置成通用I/O口,这样就能通过编写DSP程序,在上电时通过DSP的多通道缓冲串口配置SAA7110。
3.2 数据位拼接
由于SAA7110和BT121都是8 bit精度器件,而双口RAM的每边都是36 bit精度的存储器,但双口RAM的4个BANK通道,每个BANK各9 bit,共36 bit数据,可通过BEO~BE3信号选通,因此只有将SAA7110和BT121的8 bit数据进行拼接后才能送到双口RAM。由于双口RAM的每个BANK都是9 bit,SAA7110和BT121的8 bit数据总线接在每个BANK的低8 bit,忽略最高位第9位,直接地,形成8 bit的数据精度,完成不同数据精度位器件间的握手。
3.3 数据输出
处理完的图像数据,经D/A转换器BT121进行数模转换后,送到显示器,这个过程必须在严格的同步时钟控制下进行。SAA7110给出的同步信号包括水平同步、垂直同步、奇偶场和采样时钟,而BT121的同步信号只有空白信号(BLANK)、合成信号(SYNC)和转换时钟。当BLANK信号为1时,BT121才进行D/A转换,SYNC信号为1时才打开D/A通道。所以,2个器件间的同步信号不能直接握手,必须经过一定的逻辑转换。S-AA7110的同步信号引脚接到CPLD,由CPLD经过一定的逻辑运算后,送出符合BT121同步要求的信号。
4 系统工作方法和优化配置
4.1 系统工作方式
系统上电后,DSP从Flash读入1 K大小的程序数据,该引导程序继续将其他主程序调入SDRAM中,在以后的运行过程中,DSP自动将运行所需程序从SDRAM装入片内存储器。同时89C5l单片机对SAA7110进行初始化。当DSP准备就绪后,通知CPLD开始控制向输入端双端口RAM写入由S-AA7110采集的视频图像数据。输入缓存的存储空间分为奇、偶场空间,写满一场后向DSP发送中断信号,DSP收到该中断信号后以EDMA方式将数据读入SDRAM等待处理。在DSP读走和处理该部分数据时,CPLD继续控制向输入缓存的另一部分空间写入下一场采样数据。当DSP处理完上一场数据后,等待下一场视频数据的写满信号。采用双端口RAM作为系统的输入输出缓存,有效地避免了读写访问冲突和系统总线的冲突,极大提高了系统的执行效率。
4.2 配置L2 Cache和Memory的比例
由于片内RAM与CPU工作在同一时钟频率,比片外RAM性能高得多。C64的两级缓存机构工作特点为:片内分为两级存储结构(L1和L2),L1不能设置为映射寄存器。L1又分为L1P和L1D,L1D指的是第1级的数据缓冲,为128 K字节的两路成组相连结构缓存。L2是第2级片内缓存,大小为l 024 K(可同时存储程序和数据)。L1P和L1D都可以对L2进行存取,当L1D或L1P中没有运行所需要的数据时(即产生cache miss时),首先向L2发出申请,当L2中也发生cache miss时,将申请转发给EDMA。申请的转发将严重影响系统运行效率。所以根据算法数据流特性配置好两极缓存的大小,预先将待处理的数据读入,降低cache miss的次数以提高系统实时性。
以块匹配运动估计为例,匹配块32×32 pixel=1 K字节,加上旋转角度范围:±7°,步长为O.2°,共产生70个旋转1 K的小图像;搜索窗为96×96 pixel=9 K字节,共10 K字节,所有待进行运动估计的图像数据为80 K,完全可以读入L2Cache。这些数据可以用ODMA将数据全部读入片内L2。而这些数据是从一帧完整的图像中“扣出”的,所以搬移方式采用2D-1D的方式,QDMA支持这种高效的数据传输能方法。
4.3 基于EDMA加快数据传输
当使用双缓冲结构的时候,EDMA是另一种去除多余CPU开销的重要机制。利用EDMA,可实现片内存储器(L2SRAM)、片内外设,以及外部空间之间的数据转移。合理利用EDMA,还可以提高程序性能,由于图像处理中的数据对象通常以8 bit为一单位,利用DMA的数据交织功能把来自图像不同区域的4个数据并接为一个32位数据,大幅度地提高效率。
系统采用“乒乓”结构的数据交换,所以奇场和偶场的起始信号触发EDMA通道中断,虽然传送数据的源地址相同,但目的地址却不同。而C64的EDMA控制器提供了一种称为连接(linking)的传输机制,可以将不同的传输参数组连接起来,组成一个传输链,为同一通道服务。在链中,一个传输结束后,自动装载下一次传输所需要的事件参数。根据这个特点,为每个EDMA通道配置两组参数,用连接的方式完成“乒
乓”结构的数据读写。
5 算法程序优化
由于图像处理的数据量大,数据处理相关性高,并且具有严格的帧、场时间限制,因此如何针对图像处理的特点对DSP进行优化编程,充分发挥其性能就成为提高整个系统性能的关键。主要在下面方面的优化方法提高C代码的性能:
1)使用内联函数 C6000编译器提供的内联函数(intrinsic functions)。内联函数是直接映射为内联的C6000指令的特殊函数,可以快速优化C代码。
2)使用字访问短型数据 C6000的内联函数中的某些指令,如_add2()是对存储在32位寄存器的高16位和低16位字段进行操作。当对一连串短型数据进行操作时,可使用字(整型)一次访问2个短型数据,减少对内存的访问次数。
3)人工干预软件流水 流水是用来安排循环指令,并使这个循环的多次叠代并行执行的一种技术,通过线性汇编指令,并行处理数据处理指令。
通过以上3种方法优化,程序执行效率提高70%以上,表1中列出各种算法速度做50次运算的平均值。

实际上,在程序优化方面,还有很多的工作可作。另外,本实验室前期开发的基于TMS320C6711型DSP的图像开发板,工作频率在200 MHz,优化后对256×256大小的图像进行10~13帧/s的图像稳定,尚不能达到实时。而基于TMS320C6416的处理板,不优化就能达到18~22帧/s的处理速度,经过简单优化后,如提前进行图像块旋转并读入片内,展开循环,就能达到30帧/s的实时处理。现已移植的算法包括:基于快速搜索的块匹配法、灰度级分层法、边缘匹配法,各种算法都完全能够进行实时运行。
6 结论
该系统通过选用CPLD+DSP,既能保证系统的执行速度,也能保证可靠的逻辑控制。该系统实现一个比较完整的图像采集、传输、处理和送显的硬件实验系统,由CPLD对系统的运行逻辑进行控制,通过对编写在DSP上运行的图像处理程序进行优化后,能够实现大小为512×512像素图像的实时稳定。该稳像系统作为一个独立的图像处理系统,可完成多方面的图像处理功能,也为其他基于DSP的图像处理平台的设计提供了参考。

本视频基于Xilinx公司的Artix-7FPGA器件以及各种丰富的入门和进阶外设,提供了一些典型的工程实例,帮助读者从FPGA基础知识、逻辑设计概念

本课程为“从零开始大战FPGA”系列课程的基础篇。课程通俗易懂、逻辑性强、示例丰富,课程中尤其强调在设计过程中对“时序”和“逻辑”的把控,以及硬件描述语言与硬件电路相对应的“

课程中首先会给大家讲解在企业中一般数字电路从算法到流片这整个过程中会涉及到哪些流程,都分别使用什么工具,以及其中每个流程都分别做了
@2003-2020 中国电子顶级开发网





