作者:
K Krishna Deepak 赛灵思高级设计工程师 kde@xilinx.com
Dinesh Kumar 赛灵思高级工程经理 dineshk@xilinx.com
Jayaram PVSS 赛灵思高级工程经理 jayaram@xilinx.com
Ketan Mehta 赛灵思高级IP产品经理 ketanm@xilinx.com
赛灵思的 IP Integrator 工具可帮助您改善设计输入生产力和多核 Aurora 设计的资源优化。
客户在必须由单个 FPGA 实现的大型设计中使用多个知识产权 (IP) 实例时,面临的主要挑战之一是如何在整个系统中有效共享资源。赛灵思 Aurora 串行通信内核的共享逻辑特性使用户可以在多个实例中共享资源。Vivado® 设计套件中的 IP Integrator 工具对于充分利用共享资源至关重要。
电子行业正快速转向高速串行连接解决方案,同时逐渐舍弃并行通信标准。行业标准串行协议具有固定的线路速率和确定的信道宽度,有时无法充分利用千兆位串行收发器的功能。
Aurora 是赛灵思的高速串行通信协议,一直在行业内非常受欢迎。当某些应用领域中的行业协议实现过程太过复杂或者太耗费资源时,Aurora 通常是首选方案。Aurora 能实现低成本、高数据速率的可扩展IP解决方案,可用于灵活地构建高速串行数据通道。
需要同时对线路速率和通道宽度进行扩展的高性能系统和应用正在期待将 Aurora 作为解决方案。此外,Aurora 还被应用于 ASIC 设计以及包含多块 FPGA 的系统(用背板传输千兆位的数据)中。Aurora 采用简单的帧结构,并具有协议扩展流量控制功能,可用于封装现有协议的数据。它的电气要求与产品设备兼容。赛灵思提供 Aurora 64b66b 和 Aurora 8b10b 内核,作为 Vivado 设计套件 IP 目录的一部分。
IPI 工具将内核作为顶层模块进行可视化。标准接口之间的连接现在更加直观和智能化,在有些情况下甚至可实现自动化。
Vivado IP Integrator (IPI) 是用于复杂多核系统中资源优化的重要工具。就这一点而言,IPI 将帮助您充分利用 Aurora 64b66b 和 Aurora 8b10b 内核中的共享资源,尤其是“共享逻辑”特性。为了方便起见,我们重点介绍 Aurora 64b66b IP,同时您要了解类似技术也适用于 Aurora 8b10b 内核。
AURORA 的共享资源一览
图 1 是 Aurora 64b66b 内核的典型方框图。突出显示部分为时钟资源,例如混合模式时钟管理器 (MMCM)、BUFG 和 IBUFDS;以及千兆位收发器 (GT) 资源,例如 GT common 和 GT 通道,在图中标示为赛灵思 7 系列器件双路设计的 GT1 和 GT2。
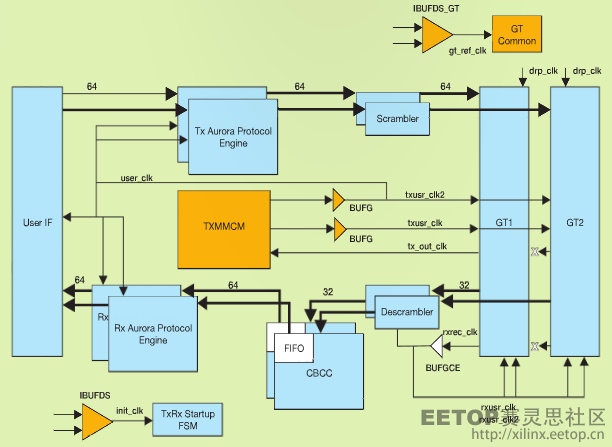
图1: Aurora 64b66b 内核的典型方框图
就像 Kintex®-7 FPGA KC705 评估套件那样,典型 16 路 Aurora 64b66b 内核所需的时钟和 GT 资源已在表 1 中列出。
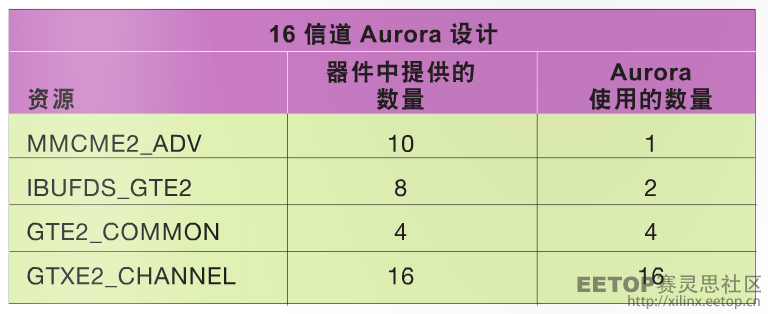
表 1–Kintex-7 FPGA KC705 评估套件上的时钟和 GT 资源利用率
FPGA 中的时钟和 GT 资源取决于所选的器件和封装类型。多个 IP 内核经常要求在系统级使用资源。因此,必须要优化利用这些宝贵资源,以降低系统成本和功耗。
AURORA 资源共享
因为多款基于 GT 的赛灵思内核都支持共享逻辑特性,Aurora 内核可配置为“内核(主机)中的共享逻辑”或“实例设计(从机)中的共享逻辑”。当在系统级进行实例化时,两种配置的组合可支持在主机与从机之间共享时钟和 GT 资源。
对于需要使用共享逻辑特性的应用,手动建立多个 IP 之间的连接有可能会产生错误,并增加总的设计输入时间。借助工具进行设计输入是一种解决该问题的方法,而赛灵思的 IP Integrator 能游刃有余地完成这个任务。
IPI 工具将内核作为顶层模块进行可视化;标准接口之间的连接现在更加直观和智能化,在有些情况下甚至可实现自动化。正确的设计规则检查被置入工具以及 IP 周围,以确保突出显示错误连接,以便设计人员在设计输入时发现它们。该工具能自动生成顶层封装文件以及调用正确的引脚级 I/O 要求,因此可帮助系统设计人员提高生产力。如果您已经设计了定制子模块,可以考虑依照赛灵思应用指南 1168,“针对 Vivado IP Integrator 打包定制 AXI IP”(XAPP1168) 对设计进行打包,并在 IPI 中使用子模块。
Aurora 的共享逻辑特性不仅可让用户在多个实例中共享资源,而且还能在相同 GT Quad 封装中使用 GT 通道,无需编辑 GT common、PLL、时钟以及相关模块。唯一的约束是“共享”内核的线路速率应该相同(允许存在谐波,只要您能接受其对时钟资源的影响即可)。
典型的共享逻辑设计在一个 Guad 中包含一个主机以及一个或多个从机实例。与大多数其它通信 IP 不同,Aurora不仅限于单个 Guad 共享。Aurora 内核的共享逻辑定义可扩展用于任意数量的受支持信道。
下面的一些实例展示了 Aurora 共享逻辑特性的应用情况。
多个单信道设计
单部 FPGA 中的多个单信道设计与多信道设计的不同之处在于前者需要通道绑定。我们可以直观地看到多个单信道设计所需的资源会在系统级线性增加。让我们考虑不同情况,并了解共享逻辑特性如何在每种情况下起作用。
我们首先从包含四条单信道的设计开始。通过实例化四个单信道 Aurora 内核,您可直接构建这类设计。如果我们实际执行该实现方案,会发现每个 Aurora 设计都有一个 GT common 实例;因此,该设计的布局和资源利用会遍及四个 GT Guad。这种方法消耗太多资源,不一定总是可行。
为实现更好的布局以及在功耗和资源方面精心优化的解决方案,所选的四个 GT 应来自同一个 GT Guad。
如果没有共享逻辑特性,而是通过手动处理所生成的设计来满足该要求,需要花费很大精力。要想有效使用共享逻辑特性,您需要生成一个主机模式的 Aurora 内核以及其它三个从机模式的 Aurora 内核,如图 2 所示。另外,还有一些其它的系统级考虑因素,例如主机内核控制了进入从机内核的时钟,所以需要对内核复位。只有用相同的线路速率配置 Aurora 内核,才能立即实现这种配置和资源优化。表 2 定量地说明了在系统中为四个单信道设计使用共享逻辑特性所能实现的优势。

表 2–在包含四条单信道的设计中使用共享逻辑所实现的资源利用率优势
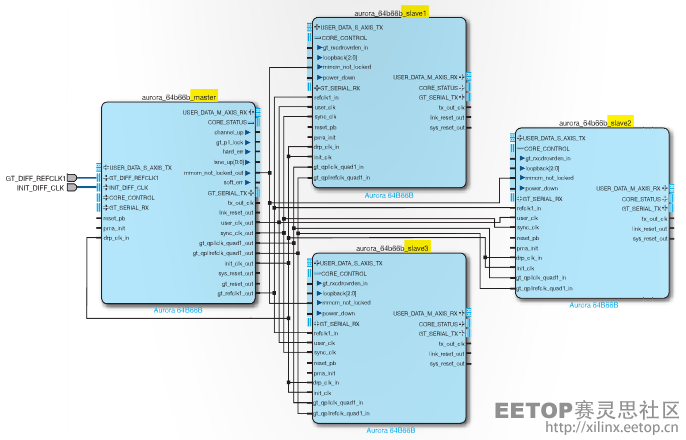
图 2–使用一个主机 Aurora 内核(左)和三个从机的共享逻辑设计
占用 12 个 GT 通道的设计
对于 7 系列 FPGA 而言,基于南北时钟的要求是如果从中间 Guad 中选择单个参考时钟源,其最多可服务 12 个 GT 通道。
让我们考虑下这种使用情况,其需要 12 个单信道设计使用尽可能少的时钟资源。
如果您将图 2 所示的“一个主机加三个从机”配置进行延伸,便可节省时钟资源。如果将这种 1+3 配置延伸为三个 Guad,那么设计一共需要六个差分时钟资源。不过,如果您选择让其中两个主机设计接受一个单端 INIT_CLK 和一个 GT 参考时钟,那么还能节省更多资源。这样我们可将该系统的差分时钟输入从六个减少至两个,从而节省 IBUFDS/IBUFDS_GTE2 资源需求(参见表 3)。设计中的 IBUFDS_GTE2 资源节省实际上还意味着可以节省外部时钟资源以及设计管脚。此外,还可针对 MMCM 进行类似的优化。
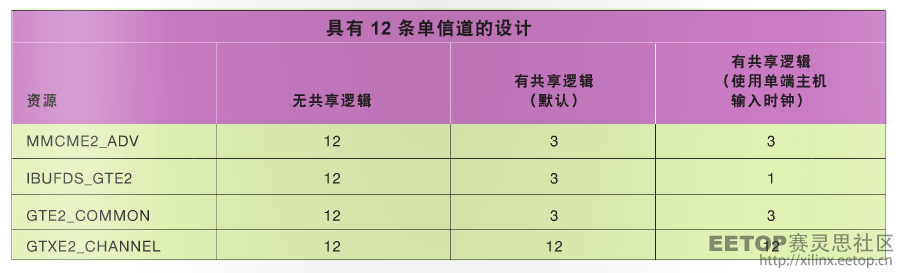
表 3–在包含 12 条单信道的设计中使用共享逻辑功能所实现的资源优势
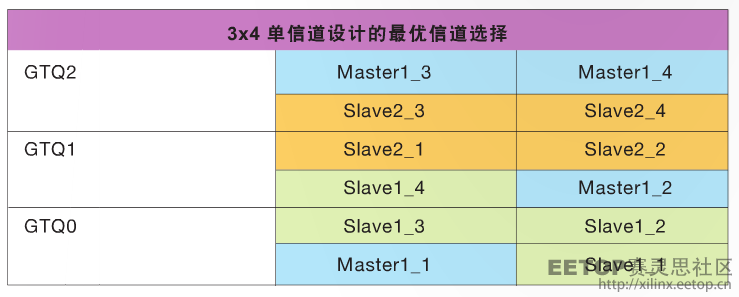
表 4–3 个四信道设计的最优信道选择
3X4 信道设计
假设需要 3 个四信道设计,如果没有共享逻辑特性,您可能要创建 3 个主机模式的四信道 Aurora 内核,然后对生成的设计进行手动处理,以获得最佳的时钟资源利用率。如果您能直接实现同样的结果呢?您可按图 3 所示对一个主机内核和两个从机内核进行定制,以实现此目的。
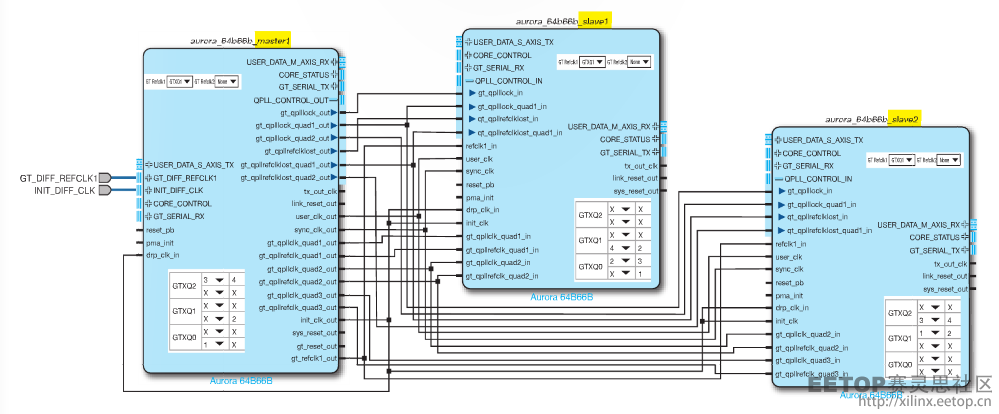
图 3–面向 3 个连续 Guad 上四信道 Aurora 设计的“1 个主机和 2 个从机”配置
而更大尺寸(16 个或以上)的单信道 Aurora 设计就更加需要共享逻辑。有时候甚至需要 48 个单信道独立双工链路。允许的 Aurora单信道链路数量仅受所选器件的可用 GT 资源数量限制。在这种情况下,如果不有效利用共享逻辑特性,很难实现这类系统设计。
该设计覆盖 12 个 Guad,因此需要 2*12 个差分时钟资源,从电路板设计角度看,这实在是项令人生畏的艰巨任务。您可利用“12 条单信道设计”案例中所提到的技术方法,减少整个系统的差分时钟和 MMCM 需求(参见表 5)。
非对称信道和其它定制优化
在视频投影机这样的设备中,主流数据以高吞吐量单方向流动,而吞吐量较低的反向通道则用来传输辅助或控制信息。在此类应用设备中,采用全面的双工链路意味着使用更少的带宽,本质上会降低系统设计的投资回报率。这种问题的理想解决方案是:如图 4 所示,采用非对称的链路宽度以及最优的 GT 资源利用率,其中,具有较高吞吐量的数据流方向上的信道数量要多于具有较低吞吐量的数据流方向上的信道数量。
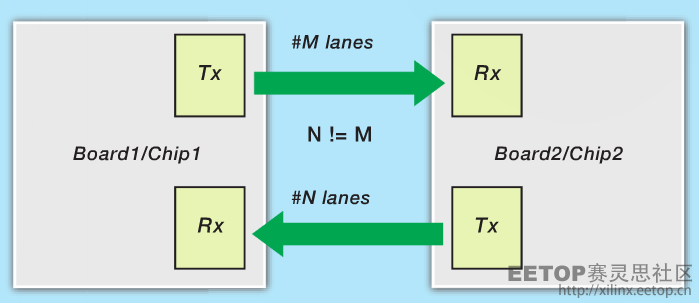
图 4–用 Aurora 实现跨链路的非对称数据传输
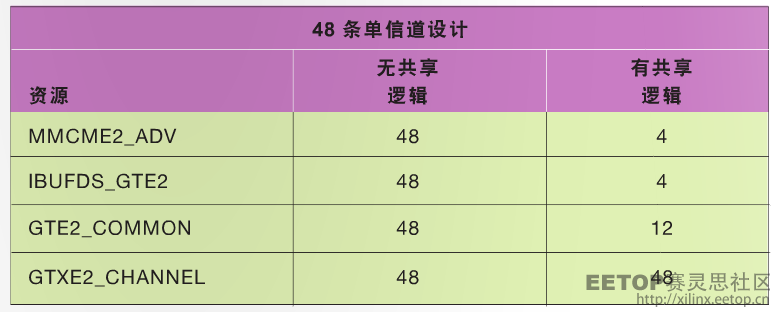
表 5–在 48 条单信道设计中使用共享逻辑特性所实现的资源优势
由于 Aurora 内核中现有的数据流模式(单工/双工),目前只能以相同的 TX 和 RX 信道数量来配置内核。要想使两个方向的信道数量不同,您需要为每个方向生成两个 Aurora 单工内核。赛灵思应用指南 1227,“采用 Aurora 64B/66B IP 核的非对称信道设计” (XAPP1227) 中介绍了在 7 系列 FPGA 上构建非对称信道设计的方法。
另外一个有用的设计策略是 BUFG 资源优化。通常,为了实现在相同或不同线路速率下工作的多个 Aurora 内核,系统设计人员需要知道器件具体的时钟要求和限制。要想实现很多条 Aurora 链路,就需要为每条链路生成时钟。节约时钟资源会提高系统的性价比。如果系统设计具有多个模块,而且时钟资源 (BUFG) 紧张,那么应考虑用 BUFR/BUFH 代替 BUFG。建议您使用相同类型的缓冲器驱动 GT 内核的两个 TX 路径用户时钟。
7 系列 Aurora 内核需要一个额外的动态重配置端口 (DRP) 时钟输入,否则将需要使用一个 BUFG。如果 Aurora 的自由运行时钟频率选定在允许的 DRP 时钟范围内,那么 Aurora 输出的自由运行时钟可以重复使用并连接回到 DRP 时钟。这样您可节省所生成设计中的 BUFG 数量。在为多个 Aurora 设计选择线路速率时,您应记住:
如果线路速率是整数倍数,便于时钟推导和在多条链路之间共享,这样您就可共享时钟资源。如果将共享逻辑特性延伸到谐波线路速率,您就可以通过少量的额外时钟分频器为从机 Aurora 内核生成所需的输入频率。
未来机遇
Aurora 具有很高的灵活性,可用来创建多种系统配置和应用。在赛灵思 Vivado IP Integrator 这样的强大工具帮助下,较高的设计输入生产力和系统级资源共享正在加速 All Programmable 应用领域的创新。凭借赛灵思 UltraScale™ 架构,具备更多 GT 通道的器件可受益于更强的 GT 线路速率支持,因此能够实现更多的设计可能性和更高的资源利用率。

本视频基于Xilinx公司的Artix-7FPGA器件以及各种丰富的入门和进阶外设,提供了一些典型的工程实例,帮助读者从FPGA基础知识、逻辑设计概念

本课程为“从零开始大战FPGA”系列课程的基础篇。课程通俗易懂、逻辑性强、示例丰富,课程中尤其强调在设计过程中对“时序”和“逻辑”的把控,以及硬件描述语言与硬件电路相对应的“

课程中首先会给大家讲解在企业中一般数字电路从算法到流片这整个过程中会涉及到哪些流程,都分别使用什么工具,以及其中每个流程都分别做了
@2003-2020 中国电子顶级开发网





