作者:Jeffrey Burt
有时候,如果你在业务上持之以恒,生意就会找上门来。
数十年来,Xilinx一直是FPGA的领导者,目前仍占有60%的市场份额。英特尔近三年前以167亿美元收购了Xilinx的竞争对手Altera,占据了其余市场的大部分份额。尽管Xilinx多年来一直保持稳定增长,2018财年收入达到创纪录的25.4亿美元,较上年增长8%,但是FPGA仍然刚刚开始在数据中心领域找到自己作为计算引擎的基础。英特尔、AMD和IBM的CPU仍然是计算的主要驱动因素,在英伟达、AMD,以及前途无量的Arm的GPU加速器的辅助下,这些公司集体希望能够参与由Cavium领导的运动。其他加速器也越来越多地被使用,如FPGA和定制ASIC,但现在的数据中心仍然由CPU主导。
尽管如此,在Xilinx工作了10年的资深员工Victor Peng(他从1月份开始担任Xilinx的首席执行官)看到了这种变化,并设想了可编程逻辑芯片走入大型数据中心用户和云构建者的HPC 中心、以及常规企业数据中心的时代。
计算领域正在发生变化,这推动了对更多异构计算的需求,这些计算可以适应现有的工作量,而无需更改任何底层基础架构。特别是,从核心到网络边缘再到云的更多端点正在连接起来,并通过传感器、摄像头和其他设备实现智能,而且它们正在创建大量非结构化数据。这些数据推动了对更强的计算和更大的存储的需求,同时也推动了利用人工智能和机器学习等技术来实现更优秀的洞察力和决策的需求。
正如我们在文章《下一代计算平台》中谈到的,FPGA对机器学习和深度学习的兴趣。今年夏天,Xilinx收购了创业公司DeePhi(DeePhi主要从事神经网络和FPGA领域的业务),增加了自己的产品组合,。
Peng在硅谷Hot Chips 2018会议的主题演讲中说:“这种智能完全连成一体,这种技术的确正在出现,而且真的是刚刚起步,特别是从今天的角度来看,智能不仅意味着某种级别的某种处理器(在许多情况下是SoC),而且因为所有这些应用都具有某种形式的人工智能,通常是某种形式的机器学习,所以它们同样也被集成到一起。之所以如此令人兴奋,是因为它不仅已经对人们的日常生活产生影响,还因为它只是刚刚出现,它将对人们的生活产生深远的影响,因为变化正在以指数级的速度发生。”
Peng指出,一些预测说,在不久的将来,每年的数据量将超过10个ZB,“从中获取价值通常意味着要处理数据并以某种形式从原始数据中提取信息,这推动了超大规模数据中心服务器数量的强劲增长。数据中心的扩展要比我们所见过的大得多,计算、存储和内存都在增加,如果你看看以指数级速度增加的数据处理和总存储空间,你就会发现到目前为止数据中心的能力尚可以跟得上需求。”
(有趣的是,这一切都是由大型数据中心用户的各种形式的广告收入以及云构建者的原始基础设施服务推动的。)
然而,在这种情况下,有一个很大的“但是”,那就是摩尔定律,Peng称之为“非常大的生存挑战”。摩尔定律缩小了晶体管的尺寸,可以在给定的区域内集成更多的晶体管,以实现更多的功能和更低的成本。在过去的50年里,摩尔定律一直很好地为行业服务,而现在它已经走到了穷途末路。
Peng表示:“这是我们所有人心中根深蒂固的想法,即便是科技行业以外的普通消费者,他们也希望更快、更便宜。每一年,对于所有的电子产品,我们都会期望在同样的价格下,产品的性能会变得更好,这是物理定律。所以,当摩尔定律不再为我们服务时,问题是非常严重的。”
多年来,芯片制造商已经采取了很多措施来跟上摩尔定律的步伐,包括增加更多内核、在内核中驱动线程,以及利用加速器。但是Peng说,使系统更快更好不仅要通过处理器技术实现,而且要通过架构实现。架构有其自身的挑战,特别是功率和密度,而这也限制了性能。
Peng说:“在过去的40年里,计算主要集中在CPU和微处理器上。从2000年开始,摩尔定律开始失效。从2010年开始,事情开始向异构系统发展,计算被划分为通用处理器和固定的硬件加速器。它可能是GPU或MPU,当然还有ASIC的复兴,特别是在机器学习方面。”
机器学习和其他新工作任务,以及联网智能设备的激增(数以百亿计,正在向数千亿计激增)正在推动对芯片技术的新一轮投资,以及对可配置和可修改的硬件平台的需求。异构架构设计将是推动性能向前发展的关键。Peng表示:“对于机器学习和所有连网的设备和系统,你无法让它们固定不变,因为你无法预测在部署时需要满足的所有需求,而且你不想通过改变物理器件来完成设备的功能。这种不仅能够在软件层面进行更改,而且能够在硬件层面远程更改大型智能设备的概念正在变得越来越强大,为了实现未来的构想,这是绝对需要的。”
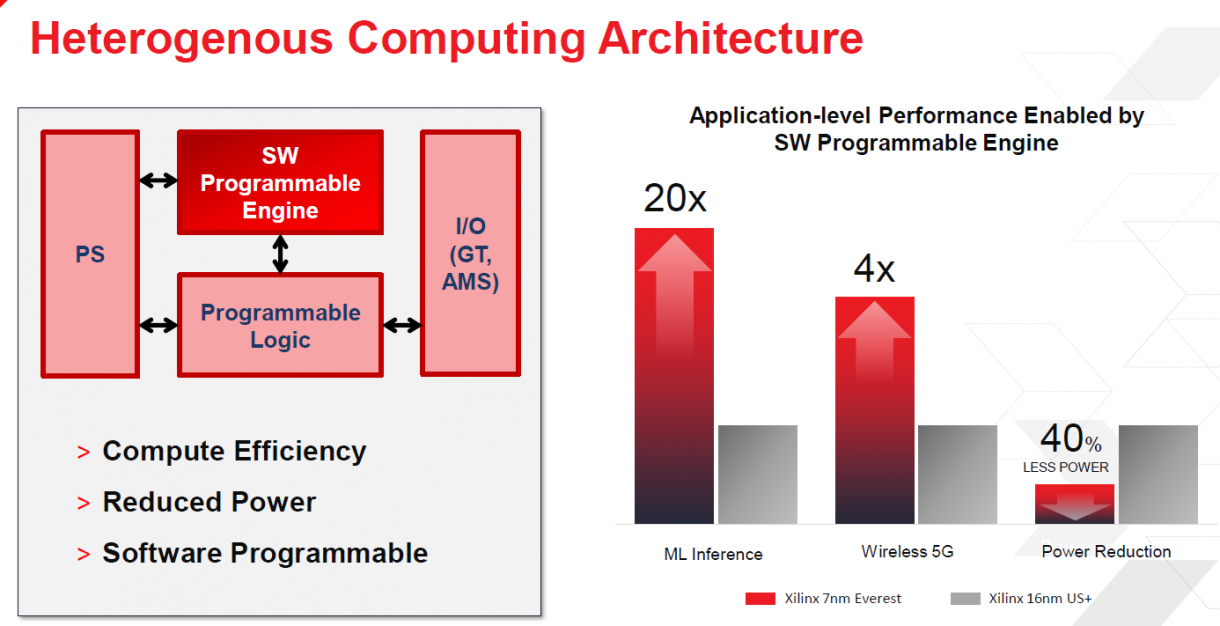
在Hot Chips会议上,Peng和Xilinx的其他人员在演讲中谈到了公司即将推出的产品,包括即将推出的自适应计算加速平台(ACAP)和7nm“Everest”SoC。Xilinx在3月份首次讨论了ACAP,虽然在Hot Chips会议上没有进行深入探讨(很可能会在10月份的Xilinx开发者论坛上进行),但Peng确实花了一些时间论述。Xilinx表示,ACAP将为公司目前16nm FPGA的机器学习推理带来20X的性能,为5G网络带来4X的性能。Everest SoC将于今年晚些时候在台积电7nm工艺试产。
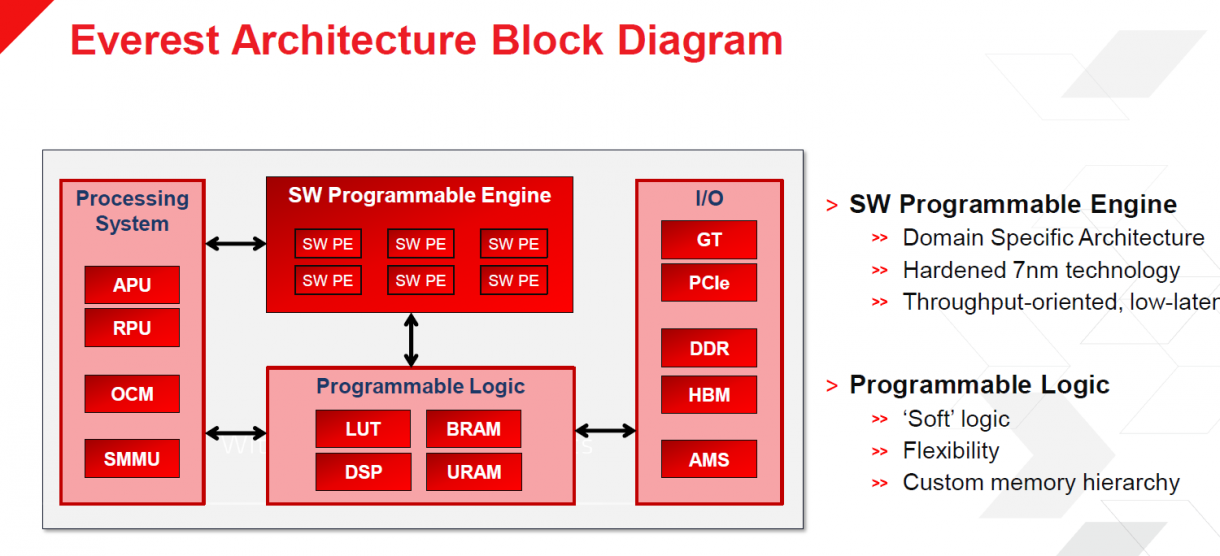
ACAP的关注点在于适应性和可编程。该平台的可编程引擎将首先处理机器学习推理和5G网络的工作。架构的核心是组块阵列,每个组块相互连接,有各自的本地存储,而且可以扩展,以针对特定的应用。Xilinx将提供一系列针对广阔的新市场的SKU。可编程逻辑将包括DSP、LUT、URAM和BRAM。根据Peng的设想,该架构将允许用户对架构进行编程,以最好地满足应用的需求。这使得组织能够将相同的芯片部署到不同的工作中。
Peng 表示:“这将使内核和DSA进出的速度更快,同时减少设计限制。它适用于多个市场。关于数据中心和云有很多讨论,但由于其灵活性和深度,它将服务于所有市场。该架构是可扩展的,因此它将用于汽车应用、云应用,以及介于两者之间的东西,例如通信、基础设施。它不仅软件可编程,硬件也可编程。”
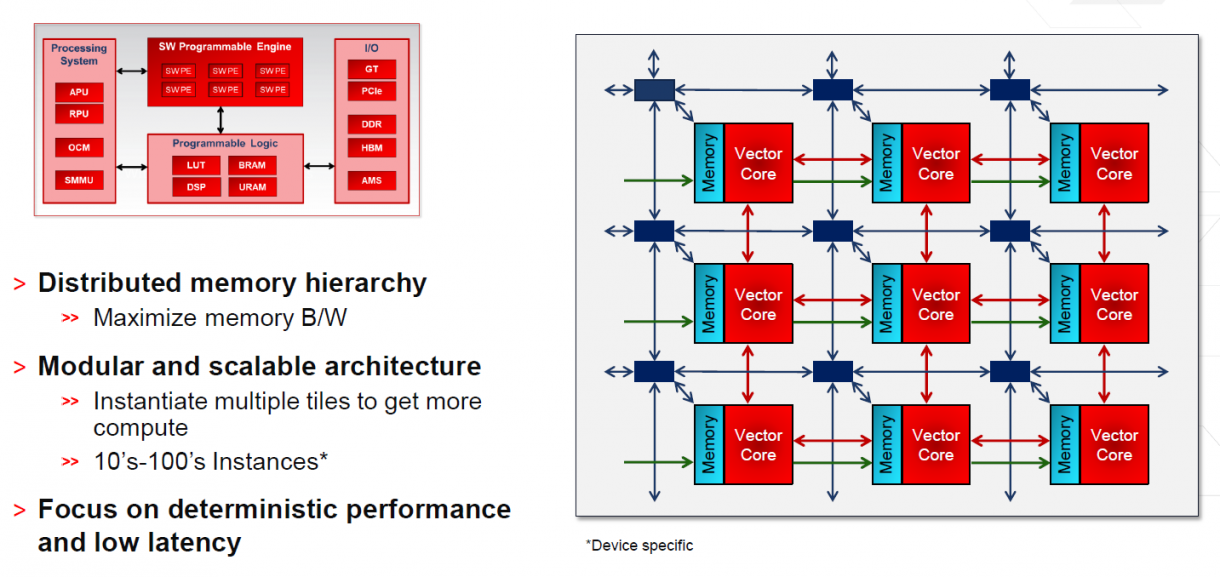
它还将带来更高的吞吐量、更低的延迟和更低的功耗,在谈论现代工作任务时,这些因素都与频率一样重要。
Peng 表示:“如今,尤其是由于人们对机器学习的关注,我们陷入了对于尖端技术的狂热。这让我想起了上世纪90年代的兆赫战争。这真的不重要,重要的是应用的加速。我们运行这些东西通常是几百兆赫或一千兆赫左右,并不会太高。原因在于,由于我们的架构普遍具有适应性,我们有很多分布式片上存储器和连接性可以自定义,甚至端口的部分配置也可以自定义。你不仅可以优化数据路径和数据流,还可以优化内存层次和带宽,以及大量的片上带宽。”
来源:本文由 公众号 半导体行业观察

本视频基于Xilinx公司的Artix-7FPGA器件以及各种丰富的入门和进阶外设,提供了一些典型的工程实例,帮助读者从FPGA基础知识、逻辑设计概念

本课程为“从零开始大战FPGA”系列课程的基础篇。课程通俗易懂、逻辑性强、示例丰富,课程中尤其强调在设计过程中对“时序”和“逻辑”的把控,以及硬件描述语言与硬件电路相对应的“

课程中首先会给大家讲解在企业中一般数字电路从算法到流片这整个过程中会涉及到哪些流程,都分别使用什么工具,以及其中每个流程都分别做了
@2003-2020 中国电子顶级开发网





