1 引言
对于逻辑芯片的嵌入存储器来说,嵌入式SRAM 是最常用的一种,其典型的应用包括片上缓冲器、高速缓冲存储器、寄存器堆等。除非用到某些特殊的结构,标准的六管单元(6T)SRAM 对于逻辑工艺有着很好的兼容性。对于小于2Mb 存储器的应用,嵌入式SRAM 可能有更好的成本效率并通常首先考虑。
Xilinx 公司SRAM型FPGA 主要由配置存储器、布线资源、可编程I/O、可编程逻辑单元CLB、块存储器BRAM 和数字时钟管理模块组成。它包含了分布式RAM,位于CLB中。每个CLB包含了16 × 1bit的SRAM结构。BRAM的加入既增加了RAM的容量,也可构成大型LUT,更完善了CLB 的功能。
2 BRAM块划分
现代数字系统对存储器容量的存储速率要求越来越高,读访问时间就是一个重要参数,它是从地址信号的出现到存储在该地址上的数据在输出端出现的时间延迟。提高BRAM 读取速度的一个有效办法是减小位线和字线上的总负载电容,这可以通过减少连接在同一字线和位线上的存储单元数目来实现,即采用存储阵列分块技术。本电路采用设计多个BRAM的方法,每个BRAM都有自己的译码电路、敏感放大器和数据通道,各个BRAM 独立工作,每个BRAM 的读取时间得到了大大提高。
3 BRAM块设计
3.1 BRAM与布线资源接口
FPGA 中每个BRAM块都嵌在内部连线结构中,与BRAM 直接相连的有RAMLINE、VLONG 和GLOBAL。左边32根RAMLINE提供BRAM的地址输入,也可以提供控制信号(CLK、WE、ENA、RST)的输入。左边两组16 根RAMLINE 一起布线提供BRAM双端口的数据输入,右边两组RAMLINE提供BRAM双端口数据输出通道。4 根GLOBLE全局时钟线优化用作时钟输入,提供较短的延迟和最小的失真。VLONG也被专门用作BRAM中WE、ENA、RST的控制输入。RAMLINE 为BRAM专有布线,如从水平方向的SINGLE、UNIHEX、BIHEX通过可编程开关矩阵PSM 把信号输送到RAMLINE 上,进而送到BRAM 用作地址、数据。而BRAM 的输出也通过RAMLINE最终送到HLONG上。
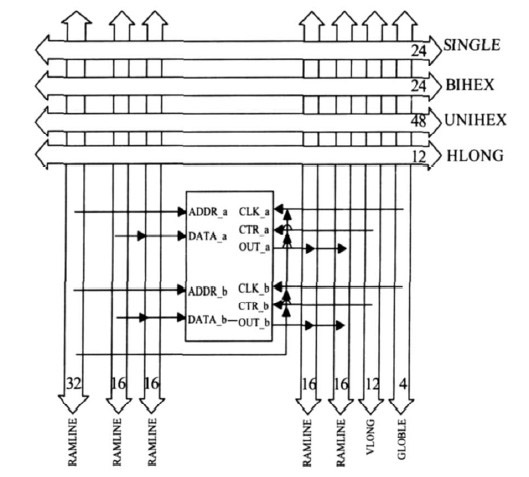
图1 BRAM周围布线
相邻BRAM 的RAMLINE 也可通过三态门连到下一级的RAMLINE,于是整列中的BRAM 可共享RAMLINE 上的数据。每个BRAM与FPGA其他电路的相连主要通过水平方向的4 组主要互连线完成。
3.2 BRAM内部设计
BRAM为真正的双端口RAM,两个端口完全独立,每个端口可以配置为读写端口,并可以把BRAM配置成特定的数据宽度。
3.2.1 可配置数据位宽实现方法
配置逻辑中三位控制信号WIDTH_SEL《0∶2》连到BRAM中,同时对地址宽度、数据宽度进行控制。
由于BRAM可以实现1、2、4、8、16 位的任意位宽,所以地址总线宽度、数据总线宽度都必须满足其中任意一种模式下的要求。于是设计时使地址总线宽度为各种模式下的最大值,即1位时的地址宽度《11∶0》,其他模式下可使不用的地址位使能无效,进而获得所需的地址位。数据总线宽度也设置为各种情况下的最大值,即16 位时的数据宽度《15∶0》,其他情况下选择有用的数据位进行存储。
表1可见WIDTH_SEL《0∶2》对地址使能的控制,主要在于对地址《11∶8》的控制,其他位地址《7∶0》则一直有效。
表1 不同数据位宽的地址使能

由WIDTH_SEL《0∶2》另外译码产生一组数据控制信号,分别为S_1、S_2、S_4、S_8、S_16 控制数据如何分配到位线上。这当中* 根位线实行了分片,每片4 根:
S_1有效:DI《0》可分配到16片中的任何一片上。
S_2有效:DI《0∶1》可分配到《0∶1》、《2∶3》、《4∶5》?任何相邻两片上,每片1 位数据。
S_4有效:DI《0∶3》可分配到《0∶3》、《4∶7》、《8∶11》、《12∶15》任何相邻四片上,每片1 位数据。
S_8 有效:DI《0∶7》可分配到《0∶7》或《8∶15》 8片上,每片1 位数据。
S_16 有效:DI《0∶15》刚好分配到16片上,每片1 位数据。
至于上述究竟存储到哪些片上以及具体存储到片内哪根位线上则由列译码控制。
3.2.2 译码控制
行译码采用了常用的3-8 译码器,3-8 译码器内由与门组成。第一级用两个3-8 译码器,输入端接入行地址ADDR《5∶0》,第二级用64 个与门把第一级译码进一步译出来,可实现64 行中选出1 行。

图2 64 选1 行译码
列译码相对较复杂,首先将列地址分为两组,一组用于片选译,一组用于片内译码。片选地址由ADDR《11∶8》组成,片内译码由ADDR《7∶6》组成。
片选地址译码由地址和地址使能组成,而地址使能则是由WIDTH_SEL《0∶2》配置决定的。

图3 片选译码
译码所得的A《11∶8》_DEC《0∶15》即可实现片选存储。当配置为1 位时,4 位地址均有效,译出的16位中只有1 位有效,只能选择16 片中的1 片。当配置为2 位时,ADDR《11》使能无效,译出16位中有连续2 位有效,能选择16 片中连续2 片。当配置为4 位时,译出16 位中有连续4 位有效,能选择16 片中连续4 片。配置为8 位就能选择16 片中的上8 片或下8 片。配置为16 位,4 个地址均无效,译出的16 位全有效,16 片全选。经过了片选的一级译码,列译码还需经过第二级的片内译码。

图4 片内译码
A《11∶8》_DEC与A7 译码均为低有效,A6译码为高有效。之所以能够用或门译码,是因为没被译码的一对BL 和BLN 位线上的数据是不会被写入存储单元的,如A7《0》为1,A《11∶8》_DEC为1,BL《0》与BLN《0》均为1,即使字线打开了,它们也是不会被写入存储阵列的。而被译码选中的一对位线,BL与BLN 互补,它们上的数据即可被写入存储单元。
3.2.3 位线充电电路
对位线的充电共有两对充电管和一对上拉管,宽长比在设计上也是有讲究的。上拉管一直开启,为倒比管。栅极接平衡管的M1 和M2 时序要求较高,因为它们的宽长比较大,为主要充电管。在BRAM总使能信号ENA和时钟CLK有效时工作,进行预充电。在CLK 下降沿,M1 和M2 短暂关闭可执行读操作。M1、M2和平衡管都在Pre1_BL信号控制下工作。
Pre1_BL 需在数据线与位线之间的开关管打开时关闭,不影响数据的读操作。Pre1_BL信号受到数据线与位线的开关管控制信号A 的约束,图4 的结构即可避免Pre1_BL与A的时序冲突,在A有效时,Pre1_BL无效,且当A 关闭时,Pre1_BL 延迟开启。
而M3 和M4 管则由Pre2_BL信号控制,Pre2_BL由BRAM全局信号ENA、CLK 和WE 一起控制。由于BRAM 在进行写操作时,也可镜像地输出写入的数据,即也做了读操作。为了更好地在写入时也读出,且满足频率要求,有必要增加这一充电管。

图5 Pre1_BL 信号产生电路

图6 位线充电电路
4 BRAM应用
作为随机存取存储器,BRAM 除了实现一般的存储器功能外,还可实现不同数据宽度的存储,且可用作ROM,以实现组合逻辑函数。当初始化了BRAM后,一组地址输入就对应了一组数据的输出,根据数据和地址的对应关系,就能实现一定的函数功能,BRAM 之所以能实现函数逻辑,原因是它拥有足够的存储单元,可以把逻辑函数所有可能的结果预先存入到存储单元中。如实现4 × 4 二进制乘法器:

即由地址来查找数据,如同LUT。在FPGA 中,还可用BRAM来实现FIFO中的存储体模块,CLB实现控制逻辑,设计紧凑,小巧灵活。

图7 4 位乘法器
5 结论
如今系统越来越高级,数字电路也高度集成,存储器也越来越多地应用于嵌入式芯片中。本文设计了一种应用于FPGA 的嵌入式存储器结构,符合一般的双端SRAM 功能,且具有FPGA 功能块的可配置选择,灵活性很高。

本视频基于Xilinx公司的Artix-7FPGA器件以及各种丰富的入门和进阶外设,提供了一些典型的工程实例,帮助读者从FPGA基础知识、逻辑设计概念

本课程为“从零开始大战FPGA”系列课程的基础篇。课程通俗易懂、逻辑性强、示例丰富,课程中尤其强调在设计过程中对“时序”和“逻辑”的把控,以及硬件描述语言与硬件电路相对应的“

课程中首先会给大家讲解在企业中一般数字电路从算法到流片这整个过程中会涉及到哪些流程,都分别使用什么工具,以及其中每个流程都分别做了
@2003-2020 中国电子顶级开发网





