摘要: 根据CMMB中LDPC 码校验矩阵的结构特点, 提出了一种部分并行译码结构的实现方法, 并在XILINX的VirtexIV的XC4VLX80型FPGA上实现了这种结构。该设计充分利用了LDPC校验矩阵的规律, 采用了一种适当的硬件结构和独特的存储器调用控制策略, 故可在保证高性能和较大吞吐率的情况下, 以较少的硬件资源实现两种码率的复用。
0 引言
低密度奇偶校验(Low Density Parity Check,LDPC) 码是由Gallager博士在1962年首次提出来的, 由于LDPC码的误码性能能够逼近香农限,因而在无线通信、卫星通信等领域都得到了较多应用。中国移动多媒体广播(CMMB) 中使用的就是LDPC纠错编码。在CMMB标准中, LDPC码长为9216, 可支持1/2和3/4 两种码率。作者通过深入分析CMMB中LDPC码校验矩阵的特点, 采用了一种合适的硬件实现结构, 因而在保证译码器较高性能和较快译码速度的情况下, 以较低的硬件资源实现了两种码率的复用。
1 CMMB 标准中的LDPC 译码算法
1.1 CMMB中LDPC 码的主要特征
CMMB采用规则的LDPC 码, 两种码率的LDPC校验矩阵有类似的规律。CMMB 中1/2 码率的LDPC码校验矩阵为一个4608×9216 的矩阵, 进一步可划分为256个18×9216行子矩阵。其中下一个行子矩阵是上一个行子矩阵的向右循环移36位,每一个行子矩阵的行重都为6; 也可以把它划分为25*608×36 列子矩阵, 其中后一个列子矩阵是前一个列子矩阵的向下循环移18位, 每一个列子矩阵的列重都为3。同理, 3/4码率的矩阵也可以进行类似的划分, 可划分为256个9×9216的行子矩阵, 每个行子矩阵的行重为12; 当然, 也可以分为256个2304×36, 列重为3的列子矩阵。
从校验矩阵的特点可以看出, 只要存储器能存储一个行或列子矩阵的非零元素, 则利用这些非零元素, 就可以恢复出整个校验矩阵, 从而进行译码。而且更为重要的是, 对于同种码率, 行子矩阵组和列子矩阵组之间在非零元素位置上有着潜在的对应关系。本文正是通过挖掘这种潜在的对应关系, 设计出了一种独特的存储器调用控制策略, 并成功实现了复用RAM的同时, 满足了两种码率的硬件结构。
1.2 LDPC译码算法
常用的LDPC码译码算法为置信度传递解码算法(BP decoding)。该算法相对比较成熟, 性能非常优异。但是, BP算法中的f (x) 函数包含对数运算和指数运算, 这些复杂运算大大增加了BP译码器的运算量和复杂度。Fossorier等在1999年提出了一种min-sum译码算法, 即利用一种近似的方法来处理BP算法中的f (x) 函数, 以将对数和指数运算化简为乘法和比较运算, 从而减少了译码器的运算量, 但该方法在性能上也有一定损失。后来, Jinghu Chen和Fossorier又提出了修正的min-sum算法。在码长较长的情况下, 修正的min-sum算法比BP算法性能只差0.03~0.05 dB, 而在算法复杂度上则只需要乘以一个常量修正因子。基于以上分析, 本文采用修正的min-sum算法来进行迭代更新, 此更新分为校验节点更新和变量节点更新。其迭代译码步骤分为两步。
第一步是初始化, 即对每个m和n, R0n→m=0其次是迭代过程。而每次迭代又包括以下3个步骤:

记集合N (m) 表示与校验节点相连的所有变量节点; 集合M (n) 表示与变量节点相连的所有校验节点; N (m) \n表示N (m) 中除去变量节点n, 同理, M (n) \m表示M (n) 中除去校验节点m。α一般取值为0.6~0.9, 本系统中通过C模型浮点和定点仿真, 可以得到α的最佳取值约为0.8,为了便于移位实现, 取值为0.7875或者0.8125均可。
2 CMMB中LDPC译码器的硬件实现
2.1 译码器总体结构
LDPC码的译码器通常有串行结构、并行结构和部分并行结构等。根据校验矩阵的特点,LDPC部分并行译码结构可简单分为输入和输出存储单元、VNU ( 变量节点运算) 单元、CNU(校验节点运算) 单元和中间结果存储单元。其译码器结构如图1所示。为了便于ASIC实现, 本文采用单端口RAM, 每块RAM由一个控制器控制以实现不同码率的地址初始化、读RAM、写RAM等操作。
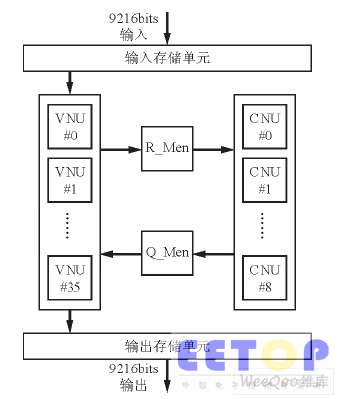
图1 译码器的总体结构。
2.2 输入和输出存储单元
检测到输入数据有效后, 可把输入的串行数据依次存到初始化RAM 里。本译码器一共有36个初始化存储器, 每个存储器的深度为256。第1个数据存到第1个RAM的0 地址, 第2个数据存到第2个RAM的0地址, 依次类推, 第37个数据再存到第1个RAM的1地址, 直到一帧9216个数据全部存满36个RAM。同样, 输出存储单元可采用类似的存储器调度方式。为了实现译码的连续性, 本设计在输入和输出部分使用了乒乓结构, 即采用两组相同的36个RAM交替操作方式。
2.3 VNU单元
VNU单元用于完成两部分工作: 一是由校验节点和初始化信息来更新变量节点的值; 二是对每一列进行硬判决。检验节点更新后的值将存储到存储单元R_Mem, 而硬判决后的比特值则存到输出存储单元, 直到满足停止译码两个条件之一时才可输出码字。第一次垂直更新时, 不用输入存储单元Q_Mem的值, 而只把输入存储单元里的初始值送到VNU单元进行更新运算即可。由于两种码率下LDPC 检验矩阵的列重都是3, 因此, 两种码率下的VNU个数都为36个, 且每个VNU结构也都是4输入的VNU。每次运算时, 都必须读输入存储单元和Q_Mem (除第一次迭代外) 中的数据的运算结果, 但应同时写入R_Mem存储单元中。本操作内部采用流水线结构, 每次迭代都延迟2个时钟周期。由于读地址都为0, 而且读地址每次加1, 因此, 执行变量节点更新运算共需花费256+2个时钟, 垂直更新结构的变量节点单元加法运算器结构如图2所示。

图2 变量节点单元加法运算器结构。
2.4 CNU单元
CNU 单元也包括两部分工作: 一是由变量节点来更新校验节点的值, 并将更新后的值存储到外部存储器; 二是对每一行硬判决后的比特进行校验, 以确定其是否满足校验方程, 也就是对每一行所对应比特进行异或, 并看结果是否为零。
若所有行的异或结构都为零, 则译码成功, 退出迭代。在CMMB标准中, 两种码率校验矩阵H的行重有所不同(分别为6和12)。为了能共用CNU模块并且共享存储器资源, 笔者设计了12输入的CNU单元, 并且使用9个CNU单元并行计算。这样, 当码率为1/2时, 1个CNU单元更新2行, 9个正好更新18行; 而当码率为3/4时, 9个CNU单元更新9行。每个12输入的CNU单元由2 个6 输入CNU单元组成, 通过1个选择器可控制CNU输出。
1/2码率时, 2个6输入CNU的输出结果可直接作为12 输入CNU的输出结果, 然后经缓存后送入Q_Mem; 3/4码率时, 2个6输入CNU的输出再经过一级比较器得出的结果, 才作为12输入CNU的输出值送到Q_Mem存储。为了方便比较最后一级比较器, 可在复用已有的两组6输入输出比较单元的同时, 还得输出两组最小值。CNU单元电路采用流水线结构来设计延时增加4个时钟周期(1/2码率) 和5个时钟周期(3/4码率)。6输入输出CNU单元的结构简图如图3所示。
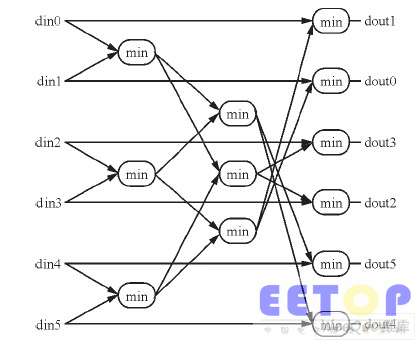
图3 检验节点单元6输入输出结构。
2.5 中间结果存储单元(R_Mem和Q_Mem)
由于两种码率时, 校验矩阵第1个子矩阵中非零元素的位置不一样。故在水平更新时, RAM的初始化地址也不一样, 需要用两组初始地址值。对两种码率来说, 第1个行子矩阵非零元素的个数都为108 (18×6或9×12)。事实上, 第1个列子矩阵非零元素的个数同样为108 (3×36)。第1个行子矩阵和第1个列子矩阵非零元素位置有着潜在的一一对应的关系。举例来说, 第1行(下标从0开始) 6个1的列位置(下标从0开始) 分别为0, 7, 19, 26, 31, 5*。若分析第5*列可以发现5*=157×36+12, 即5*列是第12列的移位。第12 列中非零位置对应的行号为0, 119, 1783=99×18+1。第5*列中非零位置对应的行号为1, 826, 2945。于是非零位置(1783, 12) 的映射为(1, 5*)。这样, 通过挖掘行子矩阵和列子矩阵中每一个非零位置的对应关系, 就能准确地得出VNU和CNU运算单元数据之间的对应关系。把这种对应关系体现到memory的调度上来, 就能准确地从R_Mem和Q_Mem中取值以进行水平和垂直更新。表1所列是中间结果存储单元和写地址的对应关系。
表1 中间结果写入单元和写地址的对应关系
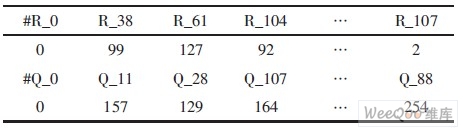
这里分别用了108个深度为256、宽度为6bits的单口RAM作为R_Mem和Q_Mem。当进行变量节点运算时, VNU输入可从Q_Mem中读取, 读数时, 首地址为0, VNU输出写入R_Mem中, 写顺序首地址为黑体数字, 运算周期为256; 当所有变量节点更新后, 接着是校验节点的运算, 同时可进行检验方程运算。此时, CNU输入从R_Mem中读取, 读数的首地址为0, CNU 输出写入Q_Mem中, 写入顺序首地址为黑体数字, 运算周期同样为256。如此交替, 便可完成迭代过程。
上述例子中, (1, 5*) 和(1783, 1) 的对应关系反映在存储单元上, 正如表1中的第2列所示。
3 译码器的性能分析及FPGA实现
作者通过C语言模型和MATLAB模型对译码器进行了浮点和定点仿真。为了达到性能和面积的平衡, 位宽的取值为6 bits, 而译码器性能只比浮点模型损失了约0.15 dB。在AWGN信道和BPSK的调制解调方式下, 当码率为1/2, 信噪比SNR为1.6 dB时, 误码率已经降至10-5以下。而在信噪比SNR为1.7 dB时, 误码率已经降至10-7以下; 当码率为3/4时, 在信噪比SNR为3.0 dB时,误码率可以降至10-6以下。
本文按照上面所描述的硬件结构, 采用XILINX的VirtexIV-XC4VLX80器件实现了CMMB标准中两种码率的LDPC译码, 并且达到了和C定点模型同样的性能。在ISE开发工具上对其进行编译时, 其具体的资源利用情况如表2所列。
表2 VirtexIV-XC4VLX80的资源利用情况
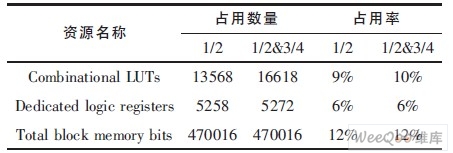
从表2中可以看出, 此结构不仅完全地复用了存储器资源, 而且最大限度地复用了逻辑运算单元。正是因为两种码率可复用RAM资源, 使memory消耗较少, 从而剩下大量的RAM资源可以用作CMMB其余部分(如解交织模块) 使用。LUT资源相对来说用得较多, 这是由于并行结构造成的, 它有36个VNU和9个CNU交替进行运算。
4 结束语
本文设计的部分并行结构的LDPC译码器能够兼容不同码率和不同校验矩阵行重的LDPC码。
运用该译码结构在XILINX的VirtexIV-XC4VLX80器件上可实现CMMB标准中两种码率的LDPC译码。事实上, 针对校验矩阵的特点, 采用一种独特的存储器控制策略, 可以最大限度地复用硬件资源, 从而大大减少了译码器的资源消耗。

本视频基于Xilinx公司的Artix-7FPGA器件以及各种丰富的入门和进阶外设,提供了一些典型的工程实例,帮助读者从FPGA基础知识、逻辑设计概念

本课程为“从零开始大战FPGA”系列课程的基础篇。课程通俗易懂、逻辑性强、示例丰富,课程中尤其强调在设计过程中对“时序”和“逻辑”的把控,以及硬件描述语言与硬件电路相对应的“

课程中首先会给大家讲解在企业中一般数字电路从算法到流片这整个过程中会涉及到哪些流程,都分别使用什么工具,以及其中每个流程都分别做了
@2003-2020 中国电子顶级开发网





