作者: 沈业兵 罗常青 安建平 程波 北京理工大学
来源:电子工程世界
Turbo码是一种低信噪比条件下也能达到优异纠错性能的信道编码。早期为了强调Turbo码接近香农限的优异性能,研究的码字长度非常大[1~2],存
在译码复杂度大、译码时延长等问题。突发数据通信以传输中小长度的数据报文业务为主,所以突发通信中的Turbo码的码长也是中等长度以下的。本文面向突
发数据通信中的信道编码应用,研究了短帧长Turbo码编译码算法的FPGA实现。实现中采用了优化的编译码算法,以降低译码复杂度和译码延时。最后仿真
和测试了Turbo译码器的纠错性能和吞吐量。
1 Turbo码编码器的FPGA实现
Turbo码的编码器是由两个RSC(递归系统卷积码)分量编码器和一个交织器组成。RSC码不仅具有系统码的优点,而且对于一个RSC码,总 存在一个具有完全相同栅格结构的NSC码(非系统卷积码)。本系统中使用两个相同的RSC编码器,生成的多项式都是G=[1,15/13],系统编码率为 1/3。
交织器的功能是利用随机化的思想将两个相互独立的短码组合成一个长的随机码。本课题中Turbo码交织器的实现是构造一个交织地址发生器,并根据输入的帧长信息,实时地产生交织地址序列。
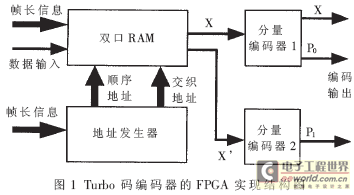
图1为编码器的FPGA实现结构图。编码前,地址发生器获取帧长信息,完成交织地址生成的准备过程。编码时,信息序列被依次写入双口RAM,待
写完一帧数据后,地址产生器开始生成顺序地址和交织地址。双口RAM按两个地址读取信息序列X和交织后的信息序列X’进行RSC编码;最后编码器输出系统
位X和校验位P0和P1。
2 Turbo码译码器的FPGA实现
Turbo码译码器比较复杂,下面从译码器的接口、内部结构、内部的时序控制、分量译码MAX-Log-MAP算法和SISO模块的实现五个方面来详细阐述译码器的FPGA实现。
2.1 译码器的接口
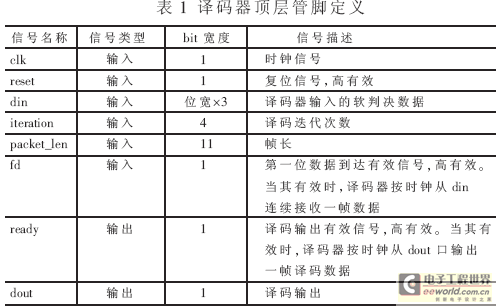
Turbo码译码器顶层模块的接口管脚如表1所示。
Turbo码译码器由两个软输入/软输出分量译码器、交织器以及相应的解交织器构成。译码是信息在两个分量译码器之间迭代运算的过程。在迭代运 算中,上一次运算得到uk的外信息Λe(uk)作为下一次运算uk的先验信息Λa(uk)。Turbo码分量译码器译码算法主要有MAP类(最大后验概率 译码算法)和SOVA类(软判决Viterbi译码算法)[3]。本文采用运算复杂度和性能都适中的MAX-Log-MAP算法。Turbo码译码器 FPGA实现的内部结构如图2所示。

地址发生器与编码器相同,用于数据的交织和解交织。输入数据存储器用于存储输入的接收数据,包括系统信息序列存储器以及各个校验序列存储器。外 信息存储器用于存储迭代译码产生的外信息。由于外信息要作为下一次译码的先验信息,所以这里的外信息存储器有两块,交替存储两个分量译码器的外信息。 SISO模块即为软输入、软输出分量译码器。整个Turbo码译码器有两个SISO分量译码模块。但为了节省资源,本方案只设计了一个SISO模块,将时 分复用作为两个分量译码器。图2中,表示接收码字中的系统位,表示接收码字中的校验位。
2.3 译码器内部的时序控制
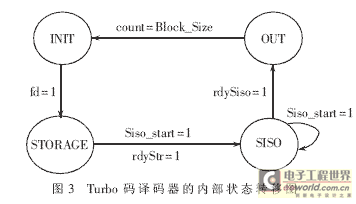
Turbo码译码器内部的时序控制由状态机完成。整个译码过程分为初始化、接收数据存储、迭代译码及硬判决输出四个过程,且对应于状态机的
INIT、STORAGE、SISO和OUT四个状态。译码器的内部状态转移如图3所示。初始状态INIT完成帧长设定等初始化工作,并完成交织地址生成
的准备过程,一旦指示第一个数据输入的fd信号有效(高有效)时,则进入STORAGE状态;状态STORAGE完成将接收数据序列存入单口RAM中,待
一帧数据写完后,指示存储完毕的rdyStr信号置高,进入SISO状态;在状态SISO下,SISO分量译码器根据设定的迭代次数对接收数据进行迭代译
码。当迭代完成时,rdySiso置高,进入OUT状态;对数据硬判决输出并计数,此时输出有效信号ready置高,待全部判决完毕后返回INIT状态。
MAP算法需要大量的乘法运算和指数运算以及大量的存储,运算十分复杂。Log-MAP算法则将MAP算法中的乘法运算转换为对数域中的加法运 算(不需要对数运算),适合工程实现。因此在工程实现时,可以将原来在对数域内的加法运算转换为取两个数的较大者加上一个修正项的运算。如果将修正项的运 算也省略,则Log-MAP算法可简化为MAX-Log-MAP算法。MAX-Log-MAP算法的主要计算步骤如下[4~5]:
(1)计算Turbo码编码网格图上分支的路径度量值:

2.5 SISO模块的实现
分量译码器的FPGA实现的SISO模块采用模块化设计,主要包括前向度量计算模块、反向度量计算及对数似然比计算模块、前向度量存储器以及归 一化度量存储器。由于前向度量计算和反向度量计算均需要计算分支度量,因此可以预先计算并存储分支度量。但在本方案中,为了节省存储空间,并没有对分支度 量进行存储,而是在前向与反向度量计算时均计算一次,而且在反向度量计算收敛后同时计算对数似然比。
用FPGA对算法进行定点实现时,需要考虑到溢出的问题。为防止计算过程中出现溢出,对前向度量和反向度量计算过程进行归一化处理。若某时刻的 归一化度量值选择当前时刻前向度量中的最大值,则归一化便是前向度量和反向度量减去此最大值。归一化后的前向度量和反向度量计算公式如下:
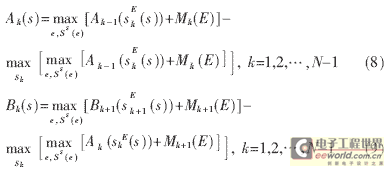
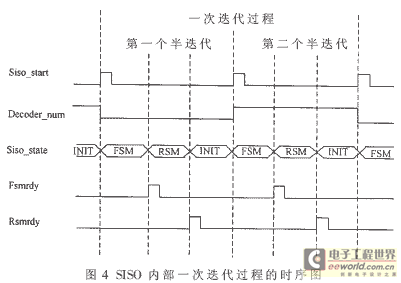
由于本方案中SISO模块将时分复用作为两个分量译码器,对应于一次译码迭代的两个半迭代过程。因此图4中的Decoder_num为低 时,SISO模块作为第一个分量译码器,进行第一个半迭代运算;Decoder_num为高时,SISO模块作为第二个分量译码器,进行第二个半迭代运 算。每次半迭代产生的对数似然比信息作为下次半迭代的先验信息。用两块RAM存储两次半迭代产生的外信息对数似然比。第一个半迭代时,从第二个外信息存储 器中读取上一次半迭代产生的外信息对数似然比作为先验信息,计算得到外信息对数似然比后存储到第一个外信息存储器中;第二个半迭代时,从第一个外信息存储 器中读取上一次半迭代产生的外信息对数似然比作为先验信息,计算得到外信息对数似然比后存储到第二个外信息存储器中。每帧数据译码的第一次迭代中的第一个 半迭代的先验信息设为0。
迭代满足迭代终止准则后,译码器停止迭代,由信息的对数似然比值硬判决输出译码结果。工程中常用的迭代终止准则是设置最大迭代次数。最大迭代次数的设定需要综合考虑误码率性能和系统吞吐量性能。
3 Turbo码编译码器的性能
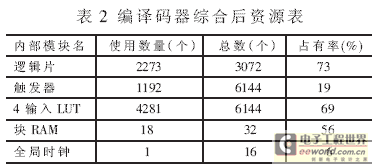
基于以上提出的Turbo码编译码器的FPGA实现方案,本文在Xilinx公司的Virtex2系列的XC2V500-6fg256 FPGA芯片上,实现了帧长在64~1 024范围之间可变的Turbo编译码器。输入数据4bit量化,内部数据位宽选择12bit,编码器模块和译码器模块在同一块FPGA芯片上实现。综合 后时钟最小周期为7.188ns ,对应最高时钟频率为139.121MHz,所占的资源如表2所示。
延迟与吞吐量是衡量译码器性能的两个主要指标。延迟定义为从第一个数据输入到第一个数据输出间的时间差。吞吐量定义为平均每秒能处理的数据量。在帧长为1 024、迭代次数为5的条件下,译码器延时约为1.4ms,吞吐量约为0.72Mbps。
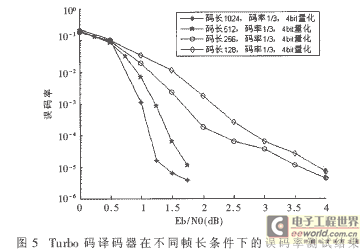
最后,对帧长为128、256、512和1 024四种条件的Turbo码译码器进行了误码率性能测试。测试系统中加入高斯白噪声,数据采用
BPSK调制,译码器5次迭代。测试结果的性能曲线如图5所示。测试结果表明,在信噪比低于4dB的条件下,跳频数传通信系统采用Turbo编译码方案,
误码率小于10-5,达到了数据传输可靠性的要求。由于译码器的帧长在64~1 024范围内可变,因此非常适合应用在突发数据通信中的差错控制中。

本视频基于Xilinx公司的Artix-7FPGA器件以及各种丰富的入门和进阶外设,提供了一些典型的工程实例,帮助读者从FPGA基础知识、逻辑设计概念

本课程为“从零开始大战FPGA”系列课程的基础篇。课程通俗易懂、逻辑性强、示例丰富,课程中尤其强调在设计过程中对“时序”和“逻辑”的把控,以及硬件描述语言与硬件电路相对应的“

课程中首先会给大家讲解在企业中一般数字电路从算法到流片这整个过程中会涉及到哪些流程,都分别使用什么工具,以及其中每个流程都分别做了
@2003-2020 中国电子顶级开发网





