作者:David Levi
首席执行官
Ethernity Networks 公司
基于赛灵思 FPGA 的可编程 COTS NIC 可将 NFV 软件应用性能提升 50 倍。
向网络功能虚拟化 (NFV) 和软件定义网络 (SDN) 的转变代表了近 20 年来最具变革性的架构网络发展趋势。由于 NFV 和 SDN 承诺系统开放性和网络中立性,因此有望给未来的通信网络和业务的成形造成深远影响。
我们 Ethernity Networks 公司正在利用赛灵思器件,率先向市场推出真正开放的、高度可编程的 SDN 和 NFV 解决方案。让我们来看一下 Ethernity 公司在首次探索 NFV 和 SDN 的前景和要求之后,是如何打造其解决方案的。
硬件和 NFV/SDN 变革遍地开花
过去几十年间的网络基础架构业务在很大程度上可谓是大型机业务模式的延续,在这种模式下,屈指可数的几家大型公司提供专有局端基础设备,而这些设备又运行专有的软件,这样构建的全部意图都是为了不与竞争对手的系统进行通信。在大多数情况下,基础架构厂商为其客户的每个网络节点都创建定制硬件,并将每个节点都构建成最低可编程性和可升级性节点,以确保那些希望对网络进行扩展或升级的客户会从同一厂商旗下购买下一代设备;或者让客户完全无法选择从其他公司购买全新网络,最终只能重蹈覆辙。
在过去五年中,来自运营商、学术机构以及厂商的新贵一直在呼吁,即通过最大化硬件与软件的可编程性来过渡到无处不在的硬件、网络中立、开放系统以及软件兼容性。NFV 和 SDN 是这一发展趋势的先锋,为这一不断成长且一定会成功的革命高举旗帜。
凭借 NFV,公司可通过软件在商用的通用硬件平台上运行各种网络功能,这与在昂贵的定制专有硬件上运行每项特定网络任务截然不同。将这些无处不在的开放式平台的可编程性最大化,使公司能够在数据中心甚至更小的网络节点中运行众多之前由特定硬件设备执行的任务。NFV 允许运营商根据需要只将给定服务的新网络软件上传到商用硬件资源,从而可以进一步减少创建新的网络服务所需的时间。运营商因此可以轻松扩展网络并为其公司选择同类最佳功能,而不用被迫购买和使用软件灵活性有限的新型专有硬件。
NFV 是有效的,因为网络中的很多节点都具有一般性的功能要求。具备一般性要求的节点包括交换机和路由器、数百万流分类、访问控制列表 (ACL)、状态流感知、深度数据包检测 (DPI)、隧道网关、流量分析、性能监控、分段、安全性、虚拟路由器和交换机。但NFV自身也面临诸多挑战。预计因特网和数据中心流量在未来几年内将呈指数级增长,因此网络局端基础设备必须能够应对流量的巨大增长。仅依靠软件可编程性并不足以使通用硬件能够随着带宽需求的增长而进行轻松扩展。无处不在的硬件需经过重新编程来优化总体系统性能。这允许厂商和运营商以“更智能,而不是更辛苦的工作”方式来利用 NFV 和 SDV,从满足运营商的最终客户(即消费者)不断提高的网络要求。真正的软/硬件可编程基础架构才是真正实现 NFV 和 SDN 的愿景的唯一方式。
SDN 同时在物理与虚拟设备中的网络控制层与底层数据转发层之间使用基于标准的软件抽象,这消除了传统分布式网络基础架构复杂且静态的本质,是一种现代的联网方法。在过去五年中,行业制定了一项标准数据层抽象协议 OpenFlow,其提供的新颖实用方法可以借助基于集中软件的控制器来配置网络架构。
具有集中软件配置的开放式 SDN 平台通过可编程性和自动化显著提升了网络敏捷性,同时大幅降低了网络运营成本。OpenFlow 等业界标准数据层抽象协议使提供商可以自由使用任何类型和品牌的数据层设备,因为所有底层网络硬件均可通过一种通用抽象协议来进行寻址。重要的是,OpenFlow 便于使用“裸机交换机”,同时避免传统厂商的套牢,使运营商同样能够自由选择目前可在 IT 基础设施的其他领域(如服务器)中轻松找到的网络。
由于 SDN 还处于起步阶段,因此标准仍在不断演进。这意味着设备厂商和运营商需要防范风险,并利用 FPGA 的硬件及软件的可编程性,以最大的灵活性对 SDN 设备进行设计和操作。目前上市的基于 FPGA 的 SDN 设备即使对于大规模部署也相当实惠。基于 FPGA 的 SDN 设备具有高度的高硬件与软件灵活性并且尽可能符合 OpenFlow 协议要求。
性能加速需求
或许,对 NFV 和 SDN 而言,要超越开放性最关键的要求就是高性能。尽管 NFV 硬件看起来比专有系统更便宜,但 NFV 架构需要保持极富竞争力的大数据量,满足下一代网络的复杂处理要求并不断提升能效。
实际上,NFV 基础设施小组规范 (Infrastructure Group Specification) 包含一个特殊部分,其描述了对加速功能的需求,以提升网络性能。此规范描述了处理器组件如何将某些功能转移到网卡 (NIC) 以支持某些加速功能,包括 TCP 分段、互联网协议 (IP) 分片、DPI、数百万条目的过滤、加密、性能监控/计数、协议互通与 OAM 以及其他加速功能。
驱动这种加速的主要引擎是 NIC,其配备了物理以太网接口,供服务器连接到网络。如图 1 中所示,当某个数据包通过 10GE、40GE 或 100GE 端口到达 NIC 时,根据标签信息(如 IP、MAC 或 VLAN)将数据包放置在虚拟端口 (VP) 或代表特定虚拟机 (VM) 的队列中。随后位于服务器上的合适的虚拟机直接对数据包进行 DMA 访问以进行处理。每个虚拟网络功能 (VNF) 都在不同虚拟机上运行,并且某些网络功能需要使用多个甚至数十个虚拟机。
OpenFlow控制硬件加速功能,比如NIC上的硬件加速功能可以视为是SDN交换机的扩展。可在多个虚拟机和/或内核上通过部署多个VNF来为众多功能处理NFV性能。这为NFV带来了两大性能挑战。第一项挑战在于“vSwitch”,这通常是一个软件,用来处理以太网NIC与虚拟机之间的网络流量。第二项性能挑战在于均衡在多个VM之间输入的40/100GE数据。添加IP分片、TCP分段、加密或其他专用硬件功能时,NFV软件需要辅助以满足性能需求并降低功耗。理想情况下,其外形应该比较紧凑,以减少存放网络设备所需要的板级空间。
为处理 NFV 挑战和各种网络功能,用于 NFV 和 SDN 的 NIC 卡必须性能极高,而且尽可能灵活。多家芯片厂商都试图成为第一家上市 NFV 硬件的厂家,他们已经提议构建针对 NIC 卡的平台,它们各自都具有不同程度的可编程性。Intel 目前是主要的 NIC 组件提供商,配有用于加速数据包处理的 DPDK 包。EZchip 提供了运行 Linux 并可用 C 语言编程的 NPS 多线程 CPU。Marvell 为其 Xelerated 处理器提供了两个完整的数据层软件套件以用于城域以太网和统一光纤应用接入(Unified Fiber Access Application),这两个套件由运行在 NPU 上的应用程序包和运行在主机 CPU 上的控制层 API 组成。Cavium 已经为其 Octeon 产品系列选择了更通用的软件开发套件。Broadcom、Intel 和 Marvel L2/L3 交换机主要用于搜索和 vSwitch 负载转移。同时,Netronome 的新款 Flow-NIC 配备了能在该公司的专用网络处理器硬件上运行的软件。
尽管所有这些产品都声称是开放式 NFV 方法,但实则不然。所有这些方法都涉及到苛刻并且可以说是限制过多的硬件实现方案,这些实现方案仅具备软件可编程,并且在 SoC 或标准处理器方面再次依赖于苛刻且专有的硬件实现方案。
用于 NFV 性能加速的 ALL PROGRAMMABLE ETHERNITY NIC
要加强可编程性同时还要大幅提高性能,很多公司都在研究一种能将现有 CPU 与 FPGA 结合使用的组合方法。在过去两年中,很多数据中心运营商(尤其是 Microsoft 公司)发布了论文来阐述他们通过混合架构所实现的性能大幅提升。Microsoft 发布的名为“Catapult Project”的白皮书指出,在功耗仅增加了 10% 的情况下,性能提高了 95%。Intel 指出,在数据中心 NIC 中将 FPGA 与 CPU 组合所产生的效能是其花费 167 亿美元收购第二大 FPGA 厂商 Altera 公司的主要原因。
同样,CPU 与 FPGA 组合方法也适用于在虚拟机上运行虚拟联网功能的NFV。在这种方法中,FPGA 用作完全可编程 NIC,经扩展可用来加速在服务器的 CPU/VM 上运行的虚拟网络功能。
但是完全基于 FPGA 的 NIC 卡是 NFV 的理想 COTS 硬件架构。多家 FPGA 固件厂商都可以提供固件,以提高在 FPGA NIC 上运行的 NFV 的性能。并且 FPGA 公司最近开发了 C 语言编译器技术(如赛灵思的 SDAccel™ 和 SDSoC™ 开发环境)以实现 OpenCL™ 和 C++ 设计输入和编程加速,从而进一步向更多用户推广 NFV 设备设计。
为加速 NFV 性能,NFV 解决方案提供商增加了 VM 的数量,目的是在多个 VM 上分配 VNF。在操作多个 VM 时,出现了新的挑战,这与均衡虚拟机间的流量负载同时还要支持 IP 分片有关。此外,在支持 VM 之间的交换以及 VM 与 NIC 之间的交换方面也存在挑战。纯软件 vSwitch 元件根本不具备足以解决这些挑战的性能。另外,还必须要保持VM的完整性,以便VM能够适当存储特定的突发数据包并且不会无序交付数据包。
Ethernity 的 ENET FPGA 专用于解决 NFV 的性能问题,其配备了虚拟交换机/路由器实现方案,使系统能够根据 L2、L3 和 L4 标签来加速 vSwitch 交换数据的功能,同时保持为每个 VM 分配一个专用虚拟端口。如果某个特定 VM 不可用,ENET 则可以将流量保存 100ms 之久;而一旦可用,ENET 将通过 DMA 将数据传输给 VM。我们的ENET安装了标准 CFM 数据包生成器和数据包分析器,可提供延迟测量功能,从而可以测量 VM 的可用性和运行健康状况,并且指示 ENET 的状态负载均衡器(关于每个 VM 在负载分配方面的可用性)。数据包重新排序引擎可以在某些情况下保持帧的顺序,例如,如果某个数据包出现无序移动,这可能导致对一项功能使用多个 VM。
图 2 描述了 VM 负载均衡ENET解决方案的方框图。
在图 2 中,分类模块执行 L2、L3 和 L4 字段的层级分类,以保持支持长时间活动 TCP(telnet、FTP 等不会立即关闭)的连接和流的路由。负载均衡器必须确保该连接上携带的多个数据包不会将负载均衡到其他可用的服务主机。ENET 包括老化机制功能,以删除不活动的流。
在分类模块中,我们根据 L2、L3 和 L4 字段配置了均衡哈希算法。此算法包含分段,以便负载均衡器能够根据内部隧道 (inner tunnel) 信息(如 VXLAN 或 NVGRE)来执行均衡,而 IP 分片连接则可以由特定连接/CPU 来进行处理。对于 VM 到 VM 连接而言,分类器和搜索引擎会将会话转发到目标 VM,而不是 vSwitch 软件。同时,分类器功能根据其路由器输出来为每个输入流分配报头操控规则,同时监控修改 IP 地址或卸载协议。
对于每个新流,目标选择模块的负载均衡器根据加权循环调度算法 (WRR) 技术从可用的 VM 中分配目标地址。将根据从 VM 负载监控模块派生的信息来配置 WRR。
分层流量管理器模块在可用的VM之间实现分层 WRR,并为每个 VM 保持一个输出虚拟端口,以根据优先级、VM 和物理端口分成三个调度层级。CPU 层级表示特定 VM,同时优先级层级可能在服务于特定 VM 的不同服务/流之间分配加权。ENET 通过操作外部 DDR3,可以支持 100ms 的缓存以克服特定 VM 的瞬时负载。
VM 负载监控使用 ENET 可编程数据包生成器和数据包分析器对电信级以太网服务进行监控,这符合 Y.1731 和 802.1ag 标准。VM 负载监控模块维护有关每个 CPU/VM 可用性的信息,对 VM 使用以太网 CFM 延迟测量报文 (DMM) 协议生成之类的指标。通过对每个数据包加盖时间戳并测量发送与接收之间的时间差,此模块可以确定每个 VM 的可用性,并据此指示可用VM上的目标选择模块。
资源选择模块所确定的是从主机发送至用户的哪些传出流量将被分类并确定数据包的资源。ENET中的报头操控模块将执行网络地址转换 (NAT) 以将输入地址替换为正确的 VM IP 地址,从而使NIC 能够将流、数据包或服务转发至正确的VM。对于输出流量,NAT 将执行相反操作并将数据包连同其原始IP地址一并发送给用户。此外,报头操控模块还将执行隧道封装。此时,报头操纵模块将执行分类器通过分类所分配的操作规则,并将在 CPU 操作之间剥离隧道报头或其他报头。在相反方向,其将原始隧道附加到输出用户端口。
随着运营商网络用户数量的增加,流表(flow table)的大小可能快速增加从而超过标准服务器的缓存容量。对于当前OpenFlow系统尤为如此,因为当前OpenFlow系统需要40个不同字段、IPv6地址、多协议标签交换(MPLS)和提供商骨干网桥(PBB)。ENET搜索引擎和包解析器可以支持对多个字段进行分类并提供数百万个流,因而可以从软件设备中卸载分类和搜索功能。
最后,通过ENET数据包报头操控引擎,ENET 可将卸载任何协议处理并为 VM 以及 TCP 分段或者各种协议之间的联网(包括用于虚拟 EPC(vEPC) 实现的 3GPP、XVLAN、MPLS、PBB、NAT/PAT 等)提供原始数据信息。
除了固件之外,Ethernity 还开发了我们称之为 ACE-NIC的NFV NIC(图 3)。要创建 NIC,我们将 ENET SoC 固件(已部署到电信级以太网网络中的数十万个系统中)部署到单个Xilinx Kintex®-7 FPGA 中。我们还将五个分立组件的功能集成到同一个 FPGA 中。NIC 和 SR-IOV 支持;网络处理(包括分类、负载均衡、数据包修改、交换、路由以及 OAM);100ms 缓冲;帧分段;加密。
ACE-NIC 是一款支持 OpenFlow 的硬件加速 NIC,并在 COTS 服务器中运行。ACE-NIC 将 vEPC 和 vCPE NFV 平台的性能提升 50 倍,极大降低了与 NFV 平台相关的端对端时延。新的 ACE-NIC 配备了四个 10GE 端口以及专为基于 Ethernity ENET 流处理器的 FPGA SoC 设计的软件和硬件,支持 PCIe® Gen3。ACE-NIC 还配备了与 FPGA SoC 连接的板载 DDR3,支持 100ms 缓冲并可搜索一百万条目。
Ethernity ENET 流处理器 SoC 平台使用具有专利、独有的基于流的处理引擎来处理大小可变的任何数据单元,提供多协议联网、流量管理、交换、路由、分段、时间戳和网络处理。此平台在Xilinx 28nm Kintex-7XC7K325T FPGA 上支持高达 80Gbps 的速率,或在更大型 FPGA 上支持更高速率。
ACE-NIC 附带基本功能,比如纳秒精度以内的按帧时间戳、数据包生成器、数据包分析器、100ms 缓冲、帧过滤以及 VM 之间的负载平衡。为提供多个云设备,其还能够按虚拟机分配虚拟端口。
此外,ACE-NIC 还带有 NFV vEPC 的专用加速功能。这些功能包括帧报头操纵和卸载、16K 虚拟端口交换实现、可编程帧分段、QoS、计数器和计费信息,这些功能可以由面向 vEPC 的 OpenFlow 进行控制。通过其独特的软件及硬件设计,ACE-NIC 将软件性能提高了 50 倍。
ALL PROGRAMMABLE ETHERNITY SDN 交换机
同样,Ethernity 在 FPGA 中集成 ENET SoC 固件以创建全 ALL PROGRAMMABLE SDN 交换机,并支持 OpenFlow 的 1.4 版本和全套电信级以太网交换机功能,从而加速白盒 SDN 交换机部署的上市进程。
ENET SoC 电信级以太网交换机是符合 MEF 标准的 L2、L3 和 L4 交换机/路由器,可以在分布于超过 128 个物理通道的 16,000 个内部虚拟端口之间交换和路由五个级别数据包报头的帧。其支持 FE、GbE 和 10GbE 以太网端口以及四种级别的流量管理调度层级。由于 ENET 的内在架构支持分段帧,因此 ENET 可以通过零拷贝技术执行 IP 分片和功能重新排序,这样一来,分段与重组便不再需要专用的存储和转发。此外,ENET 还具有集成的可编程数据包生成器和数据包分析器,可简化 CFM/OAM 操作。最终,ENET 可以在 3GPP、LTE、移动回程和宽带接入中运行。其支持多个协议之间的互通,这些只需要通过零拷贝操作,并且不需要重新路由帧来进行报头操控。
显然,通信行业正处在新时代的开端。我们确信可以看到 NFV 和 SDN 领域会有很多创新。NFV 性能提升或 SDN 交换机的任何新兴解决方案必须能够支持新版 SDN。随着 Intel 收购 Altera 以及寻求更高可编程性的硬件架构不断增多,我们确信处理器与 FPGA 的组合架构也会越来越多,同时还会有新的创新方式来实现 NFV 性能提升。
基于 FPGA 的 NFV NIC 加速可以基于通用处理器来提供 NFV 的灵活性,同时提供GPP 无法维持的必要吞吐量,并且还要执行 GPP 无法支持的特定网络功能加速。通过在 FPGA 平台上有效组合 SDN 与 NFV,我们可以设计出 All Programmable 网络设备,从而推动网络应用领域中全新的 IP 厂商生态系统创新。
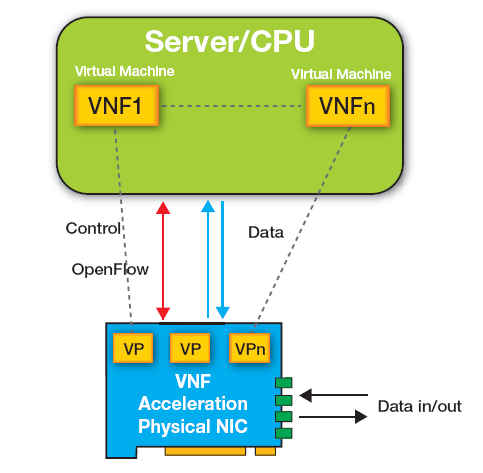
图 1 – 在数据包到达时,NIC 进入代表特定虚拟机的虚拟端口 (VP)。数据包随后通过 DMA 发送到服务器上的合适的虚拟机以进行处理。
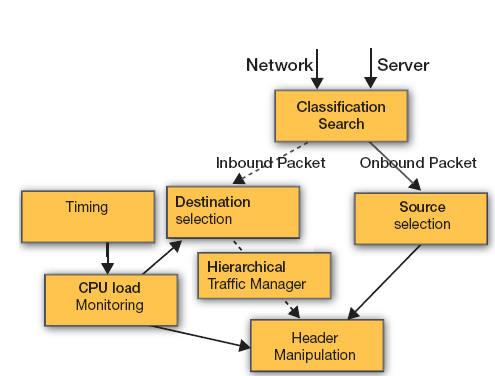
图 2 - 这一高级方框图显示了虚拟机的负载均衡和交换机。
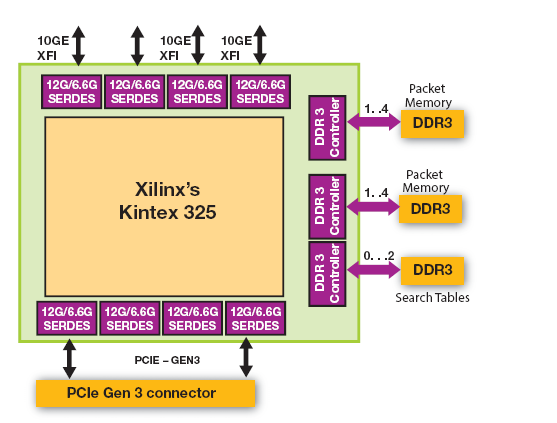
图 3 – Xilinx Kintex FPGA 位于 Ethernity NFV 网卡的中心。

本视频基于Xilinx公司的Artix-7FPGA器件以及各种丰富的入门和进阶外设,提供了一些典型的工程实例,帮助读者从FPGA基础知识、逻辑设计概念

本课程为“从零开始大战FPGA”系列课程的基础篇。课程通俗易懂、逻辑性强、示例丰富,课程中尤其强调在设计过程中对“时序”和“逻辑”的把控,以及硬件描述语言与硬件电路相对应的“

课程中首先会给大家讲解在企业中一般数字电路从算法到流片这整个过程中会涉及到哪些流程,都分别使用什么工具,以及其中每个流程都分别做了
@2003-2020 中国电子顶级开发网





