第一期:使用 C++ 库开发 OpenCL图像应用
发布者:jackzhang
时间:2015-11-26 21:43:08
作者:Stephen Neuendorffer,
赛灵思公司 Vivado HLS 首席工程师
stephenn@xilinx.com
Thomas Li
赛灵思公司 Vivado HLS 软件工程师
thl@xilinx.com
Fernando Martinez Vallina
赛灵思公司 SDAccel 开发经理
vallina@xilinx.com
随着线上图片与视频、机器人和驾驶员辅助应用的快速推广,近年来成像应用的规模和普及率均在提升。这些领域的核心算法非常相似,都需要一种能够让应用开发人员根据市场和部署目标迅速实现产品重构与差异化的开发方法。
针对这样的需求,成像应用一般先从针对CPU 的软件程序开始,使用库调用功能来调用标准函数。软件设计方法与随时可用的库相结合,不仅可以轻松启动开发工作,而且还容易在桌面上开发出功能正确的应用。
对开发人员而言,挑战在于针对执行对象优化成像应用。赛灵思 SDAccelTM 开发环境借助赛灵思 Vivado® HLS 技术,让为 FPGA 开发 OpenCLTM 应
用的开发人员能够方便地使用 C++ 库。
一组并行计算任务成像应用的关键特征之一是它们基本上是相对于周边相邻像素在空间上(对某些应用在时间上)在某个像素上开展的一组运算。因此我们可以把成像应用视为开发人员能在 CPU、GPU 或 FPGA 上执行的一组并行计算任务。
CPU 一直是应用启动最方便的目标器件。在考虑优化之前,代码一般已经在 CPU 上运行,因此可以运用丰富的现有库。在 CPU 上执行成像工作负载的问题在于可实现的持续性能。总体性能受缓存命中率 / 未命中率,以及将并行化转化为运行在多个 CPU 内核上的多个线程这个重要任务的制约。
在成像应用方面,GPU 有望提供远超 GPU 的性能,因为 GPU 的硬件是专门为成像工作负载构建的。直到最近几年,GPU 的不足之处就是在在一般成像应用方面一直采用编程模型。GPU 编程与 CPU 编程的区别在于 GPU 模型不能在 GPU 器件系列之间移植。随着针对采用 OpenCL 框架的 GPU 等并行系统的编程的标准化,这种情况已经发生变化。
FPGA 为成像工作负载提供了一种可选实现方法。开发人员可以将 FPGA 逻辑架构定制为工作负载专用线路。FPGA 架构的灵活性让应用开发人员在充分发挥定制逻辑的性能和功耗优势的同时,还能避免 ASIC 设计带来的成本和工作量。
和 GPU 一样,采用 FPGA 器件的障碍之一也是编程模型。传统上 FPGA 一直采用 Verilog 或 VHDL 等寄存器传输语言 (RTL) 编程。虽然这些语言能够表达并行性,但其精细度远低于 CPU 或 GPU 编程所要求的水平。但就和 GPU 一样,采用 OpenCL 标准,用软件编程人员熟悉的方式表达 FPGA 编程,已经克服编程模型障碍。
OpenCL 框架OpenCL 框架为表达数据并行程序提供了一个通用编程模型。该框架已发展成为行业标准,其采用所有支持 OpenCL 的器件厂商通用的平台和存储器模
型。一个器件可以定义为任何能够执行 OpenCL 内核的硬件,不管是 CPU、GPU 还是 FPGA。
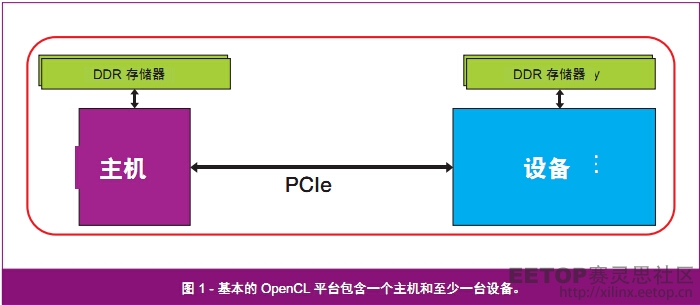
OpenCL 应用内部的平台负责定义执行应用的硬件环境。图 1 显示了构成 OpenCL 平台的主要元件。
OpenCL 平台常常包含一个一般实现在处理器上的主机。该主机负责在器件上发起任务和负责明示地协调主机和器件之间的全部数据传输。
除主机外,该平台还包含至少一台设备。OpenCL 平台中的设备是能够执行 OpenCL 内核代码的硬件元件。在 OpenCL 应用环境中,内核代码是算法中需要加速的高计算强度部分。
在 CPU 和 GPU 器件上,内核代码在器件中的一个或多个内核上执行。每个内核从器件规格来说完全相同。这种严格性迫使应用开发人员修改代码以最大限度地提高固定架构的性能。
与此相反,对 FPGA 而言,SDAccel 开发环境能根据应用内核的具体计算要求生成定制内核。因此应用开发人员能根据算法需要自由地探索实现架
构,以降低整体系统时延和功耗。
第二个 OpenCL 组件是存储器模型(图 2)。 该模型对所有厂商是通用的,用于定义统一的存储器层级,以便开发人员能够创建可移植应用。该存储器模型的主要组件有主机存储器、全局存储器、本地存储器和专用存储器。主机存储器指只能供主机处理器访问的内存空间。FPGA(设备)可见的存储器分为全局存储器、本地存储器和专用存储器。
全局内存空间一般实现在 FPGA 连接的 DDR 中,主机和设备都能访问。根据加速板上使用的具体 FPGA 不同,部分全局存储器还可实现在 FPGA 架构内部。本地存储器和专用存储器仅对在FPGA 架构内部执行的内核可见,使用 Block RAM(BRAM)和寄存器资源完全内置在架构内。
下文将介绍 SDAccel 环境利用 OpenCL 和 C++ 库实现立体成像模块匹配应用。
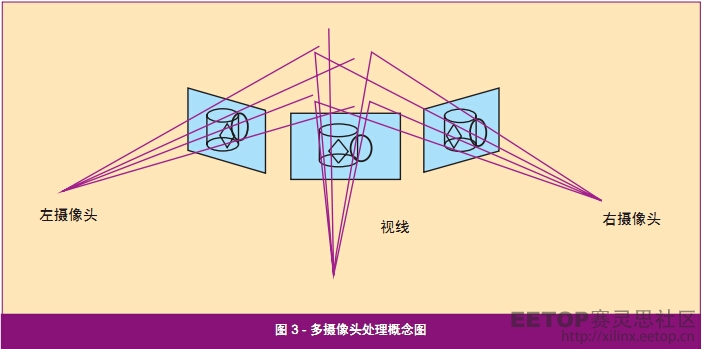
立体模块匹配立体模块匹配功能使用来自两个摄像头的图像建立位于两个摄像头视野内的物体的形状表达。如图 3 所示,该算法使用左右摄像头输入的图像搜索图像间的对应性。这种多摄像头图像处理任务可应用于深度图、图像分割和前景 / 背景分离。举例而言,这些均属于驾驶员辅助系统中行人检测应用不可分割的组成部分。
将C++ 库用于视频SDAccel 开发环境将赛灵思 Vivado HLC C-to-RTL编译器技术用作核心内核编译器的一部分,让 SDAccel 环境能够像使用用 OpenCL C 表达的内核一样使用用 C 和 C++ 表达的内核。因此应用开发人员就能使用之前在 Vivado HLS 中优化过的 C++ 库和代码提高生产力。立体模块匹配应用的主代码见下一页。
Vivado HLS 提供基于常用的 OpenCV 框架的图像处理函数。这些函数用 C++ 编写,并且为在 FPGA 中提供高性能进行了优化。在综合到 FPGA 实现方案中后,相当于每个时钟周期能同时执行数十条乃至数千条 RISC 处理器指令。
应用代码使用 Vivado HLS 视频处理函数创建该应用。该应用代码包含对 Vivado HLS 库的 C++ 函数调用和编译指示,以引导编译过程。编译指示分为用于接口定义的编译指示和用于性能优化的编译指示。
接口定义编译指示决定立体模块匹配加速器与系统其余部分的连接方式。由于该加速器用 C++ 而非 OpenCL 语言代码表达,因此应用编程人员必须提供用于匹配 SDAccel 环境中 OpenCL 模型的推测的编译指示。
标识“m_axi”的编程指示用于声明缓存的内容将存储在设备的全局存储器中。标识“s_axilite”的编程指示则用于供加速器从主机接收全局存储器缓存中的基地址。
本代码中的性能优化编译指示是数据流。数据流编译指示生成的是一个加速器,其中的不同子函数也可同步执行。
在本加速器中由于底层实现的是“hls::Mat”数据类型,数据也在每项函数之间传递。这样一来只要Split 函数生成像素,FindStereoCorrespondenceBM 函数就开始工作,无需等待生成完整的图像。这样可得到一种更高效的架构,与在各函数间等待完整帧缓存再顺序执行各函数相比,处理时延明显下降。
成像应用是一种计算密集型应用,需要用到大量现成的库。其挑战在于针对执行目标优化应用。SDAccel 环境让开发人员能够充分发挥 C++ 库的作用,为采用 OpenCL 编程的 FPGA 加快成像应用的开发速度。