无论为数以百万计的用户搜索请求提供服务还是处理超大量的信息,都需要数量庞大的计算资源,进而消耗大量能源。事实上,用于计算与冷却的能耗费用是数据中心运营的最大成本 [1]。随着数据中心的数量和规模不断增长,如果其能耗保持当前水平的话,那么预计数据中心的二氧化碳排放量到 2020年将超过航空公司[2]。因而亟需开发能够处理巨量数据的低能耗解决方案。数据中心的环保化发展是互利共赢的,服务供应商不仅能够显著降低运营成本,同时还能最大限度减少对环境的影响。
FPGA在加速Web搜索及类似信息检索等常见数据中心工作任务方面拥有巨大的潜力,因为它具备固有的并行处理与低功耗优势。充分认识到这一潜力的奥地利公司Matrixware购买了FPGA平台,但缺乏自身实施复杂信息检索应用的技术,因而公司聘请了我们联合格拉斯哥大学(University of Glasgow) 计算机系组建的团队开发 FPGA加速型专利搜索解决方案的概念验证方案。该团队成员包括三名设计人员和兼职助理研究员SteliosPapanastasious,他们在信息检索、FPGA以及系统开发领域积累了丰富的专业知识,形成了一个开发原型应用所不可或缺的技能娴熟的组合。经讨论,大家一致同意采用FPGA加速型后端进行实时专利过滤应用的开发。
项目资源在人力和时间方面受到很大制约。因此,采用HDL实施过滤算法不可行,因而我们决定采用瑞典公司Mitrionics开发的高级编程解决方案。原型应用在去年11月于奥地利维也纳举行的信息检索设施研讨会(Information Retrieval FacilitySymposium)上引起了专利研究人员的极大兴趣。处理数以百万份的专利通常需要几分钟,但若采用FPGA加速型后端,几秒钟就能反馈结果。
我们在2009年7月举行的ACM SIGIR国际信息检索研究暨开发大会(ACM SIGIR International Conference
on Information Retrieval Research and Development) 上发布了结果,介绍了相关的性能提升情况 [3],并在FPL 2009国际现场可编程逻辑大会上对架构设计进行了详细阐述 [4]。
文档过滤的输入与输出通常情况下,信息过滤任务是指检查传送进来的文档是否与一系列既定的需求信息或配置文件相匹配[5]。这种任务可在多种情况下出于多种原因而进行,例如,检测传送进入的电子邮件是不是垃圾邮件,比较专利申请是否与现有专利发生重叠,监控是否存在恐怖活动通信,监测并跟踪新闻报道,等等。面对大量涌入的文档,处理工作必须实时完成,从而确保时效性成为重中之重。鉴于此,我们的目标就是采用FPGA来实施完成计算强度最大的过滤应用,从而在节约时间和降低能耗的情况下提高文档过滤的效率。
在本文中,我们将采用Lavrenko和Croft提出的相关性模型 [6]。这一理念适用于信息过滤任务,可通过生成概率语言模型确定传入文档是否与主题配置文件存在差异。如果文档得分超过用户定义的阈值,那么就视为与主题配置文件相关。
在FPGA上实施的算法表达如下:文档可以建模为一个“词袋”,即由(t,f )对组成的D集,其中 f=n(t,d),t 表示 t 这个词在文档d中出现的次数。配置文件M为一组对 p=(t,w),这里的w加权为:
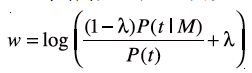
给定文档对于给定配置文件的得分计算为:
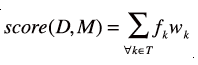
这里,T是指在D和M中都出现的词。该函数是大多数过滤算法的代表性内核算法,不同算法的主要区别在于配置文件中词的加权。
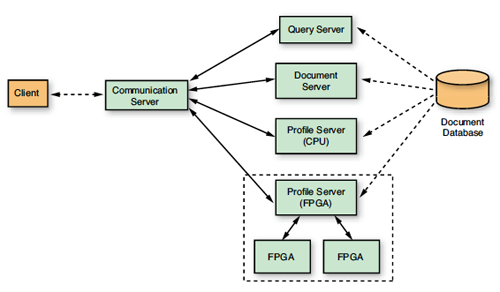
应用架构
文档过滤应用采用客户端—服务器架构,其构成形式为将基于GUI的客户由FPGA加速的部分受限于计算强度最大的任务,也就是文档与配置文件的匹配。主机系统则负责处理所有其他的任务(参见图 2)。
配置文件服务器根据从客户端获得的配置文件过滤一系列文档,并返回分数流。为了评估性能,我们同时创建了C++参考实施和FPGA加速实施方案。两种版本的实施方案基本功能相同,都能通过TCP/IP接口接收构成配置文件的文档列表,用相关性模型构建配置文件,并根据该配置文件对存储器缓冲的文档进行评分,从而通过TCP/IP向客户端返回文档分数流。可在存储器中缓冲文档流,否则会由于缓慢的磁盘存取影响应用的性能。
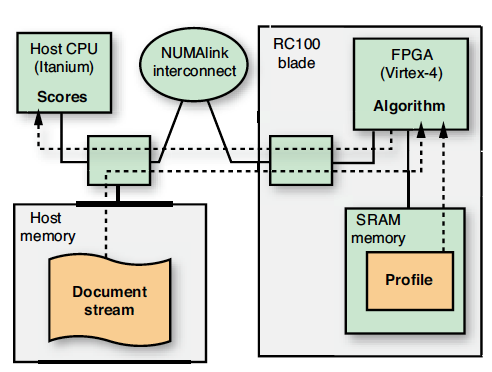
我们在具有两个RC100刀片的SGI Altix 4700设备上实施该应用,其中的每个刀片都包含两个运行频率为 100 MHz
的赛灵思Virtex®-4 LX200 FPGA;每个FPGA都通过SGINUMAlink高速I/O接口连接到主机平台,并能通过最高速度为每秒 16GB 的 128 位数据总线存取本地 64MB 的 SRAM存储库。主机系统是一套80个内核的64位NUMA设备,运行性能为64位Linux(OpenSuSE)。处理器为双核Itanium-2,运行频率1.6 GHz,其中每个处理器都能直接存取4GB 的存储器,而且能通过NUMAlink存取完整的320GB存储器空间。值得注意的是,Itanium处理器功耗约为130瓦特 [7],而每个Virtex-4FPGA的功耗仅约1.25 W [8]。
对于 C++ 语言应用而言,我们实施 Lemur 信息检索 (IR) 框架,对于与FPGA 应用的交互,我们则使用 SGI可配置专用计算 (RASC) 库。Lemur Toolkit(详情访问 www.lemurproject.org )是一套开源工具集,专为IR研究而精心设计,可支持索引以及多种相关性和检索模型。RASC 库是 SGI的专有解决方案,能够通过高性能 NUMAlink互连机制将 FPGA 与主机系统相集成。RASC 库定义的硬件抽象 API 可控制系统中的所有硬件元素。
我们用 Mitrionics 软件开发工具套件 (SDK) 将特定域的 Mitrion-C 语言转换为 VHDL。生成的VHDL 现在能够方便地指向 FPGA 器件架构。我们采用带XST 合成工具的赛灵思 ISE® 工具链来创建 Virtex-4 比特流。
高级FPGA编程
MitrionicsSDK可提供Mitrion-C作为高级语言,专用于满足在FPGA上快速开发应用之需。不过,作为后缀的C有些误导作用。尽管这种语言采用了C风格的语法,但实际上是一种遵循函数编程风格的单赋值数据流语言。Mitrion-C原生支持广泛(矢量)而深入(管道)的并行功能,因而非常适用于处理数据流的算法,例如过滤以及其他众多类型的文本和数据挖掘算法等。
Mitrion-C还提供了一种流数据类型,可配合foreachlooping构造实现流水线操作;此外,还提供矢量数据类型以支持数据并行工作,以及支持顺序列表的列表数据类型。具体而言,用户可过滤foreachloop的流输出,生成较小的流,如以下Mitrion-C代码示例所示。此外,程序人员还能用元组结构(tuple construct)创建功能强大的数据类型。最后还有一个需要指出的特性是,该语言能支持可变宽度整数和浮点数。

为了在FPGA上高效实施评分操作,我们必须解决的关键问题是高效查询配置文件以及文档流的高效I/O流。
对于文档中的每个词,应用都要查询配置文件中相应的词并获得词加权 (termweight)。由于大多数查询都找不到结果(即大多数文档的大多数词不会出现在配置文件中),因此必须首先丢弃否定词。鉴于此,我们在FPGABlock RAM中采用了Bloom过滤器[9]。BRAM的内部带宽越高,拒绝否定词的结果就越快。由于需要查询,因此配置文件必须作为某种散列函数进行实施。不过,由于配置文件的大小不能提前知道,因而我们不可能构建出完美的散列函数。不完美的散列函数会出现冲突问题,进而降低性能。
为了解决这一问题,我们采用了分档方案,即将外部SRAM分区为bin,每个bin都可包含固定数量的配置文件词。Bin的大小决定了可处理的冲突数。如需给bin分配配置文件词,只需将词ID的较下部分作为存储器地址,从而避免了实际的散列操作。
让SRAM存储器容量设定为NM配置文件词。词ID是一个无符号的整数,其范围取决于词汇量,就我们的例子而言约为 400 万个词,需要 24位。词加权为 8.32定点数,因而配置文件词需要64位。RC100上的SRAM包括4个16MB存储库,因此NM=223。Bins的数量nb=NM/b和bin地址用词ID“t”进行计算,即 (t&(nb-1)).b。
Bin的占用概率x由组合决定,置换决定bin的数量nb和描述词的数量np。这样,我们就能计算bin溢出的概率就是bin大小的函数(即bin的数量),即NM=b.nb。bin尺寸越大,查询就越慢,但是,由于SRAM存储库包括4个独立的64位可寻址双端口SRAM,我们实际上可以并行查询四个配置文件词。因此,相对性能会降低1/ceil(b/4)。我们的分析结果显示,即便对最大型的配置文件来说(16K,我们研究所用的最大配置文件为12K,不过通常配置文件比这都要小得多),b=4时(最佳性能),bin溢出概率为10-9。换言之,描述词被丢弃的概率不到10亿分之一。应注意的是,由于我们假定词汇量无限大,因而这一估算还是保守数字。
通过将文档表述为“词袋”,文档流就是文档ID、文档词对组 (document term pair set)等对列表。从物理上说,FPGA 以每秒1.6 GB的速度从NUMAlin接受128位字流。因此,文档流必须在字流上编码。可将文档词对di=(ti,fi)编码为32位:24位用于词ID(支持1,600万个词的词汇库),8位用于词的频率。这样,我们就能将4个对组合到128位字中。要标示文档的起点与终点,我们需要插入包含文档ID(64位)和标志符(64位)的报头与脚注字 (footer word)。
如上所述采用查询表架构和文档流格式,实际的查询和评分系统(图3)会非常直接。我们只需扫描输入流以检查报头和脚注字即可。报头字将文档得分设为 0,而脚注字则收集并输出文档得分。对于文档中的每四个配置文件
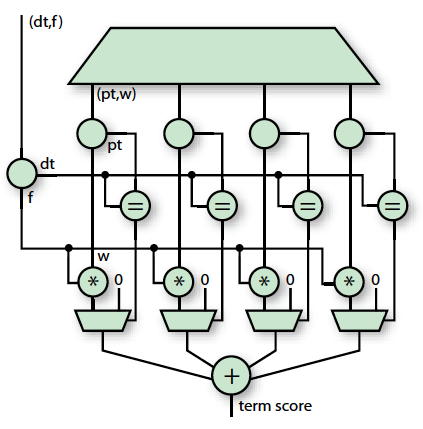
词,Bloom过滤器首先丢弃否定词结果,再从SRAM读取四个配置文件词。并行计算并添加(图4)每个词的得分。实际上,四分之三的配置文件词ID不会匹配于文档词ID;只对第四个进行实际计算。将文档中所有词的得分进行累加,最后得分流在输出到主机存储器之前与限值进行比较过滤。
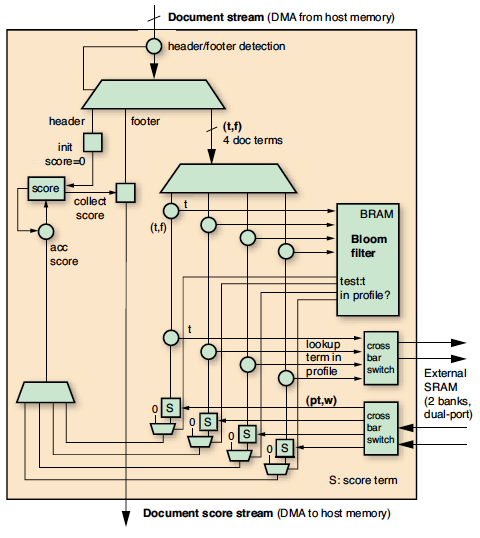
主机—FPGA接口将文档流从存储器缓冲器中传输至FPGA,并将得分流返回至客户端中。一旦从客户端接收到配置文档ID表,子进程即从主进程中分叉出来,以构建实际的配置文件,将其载入SRAM并在FPGA上运行算法。每个子进程都会产生一个独立的输出线程,以对从FPGA获得的得分进行缓冲,并通过TCP/IP将这些得分传输到客户端,从而使用网络对得分流进行多路复用。若没有该线程,网络吞吐量的波动就会降低系统性能。这种主机接口架构的主要优势在于,它具有很高的可扩展性,能轻松满足大量FPGA的需求。
大幅度提速
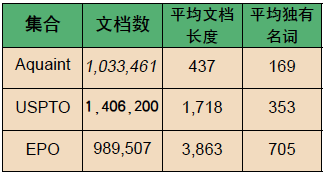
为了评估FPGA加速型过滤应用的性能,我们进行了一系列实验,将基于FPGA的实施方案与采用C++编写的运行于Altix之上的优化参考实施方案进行了比较。在比较过程中,我们使用了三个IR测试集合(参见表 1):一个是文本检索会议 (TREC) 提供的基准参考集合TRECAquaint,还有两个分别是美国专利与商标署 (USPTO) 和欧洲专利署 (EPO)提供的专利集合。我们选择上述测试集合来评估不同文档长度和大小对过滤时间的影响。
为了仿真众多不同的过滤器,我们通过选择随机文档并用标题作为请求,随后再选择请求服务器返回的固定数量的文档作为伪相关文档,来为每个测试集合构建配置文件。我们接下来使用返回的文档构建相关性模型,该模型定义了文档集合中每个文档应当匹配(就好像从网络进行流处理一样)的配置文件。配置文件中的文档数量从1到50不等,可确定增加配置文件的大小(词数和文档数)会对性能有何影响。我们将上述进程重复30次,并计算平均处理时间。
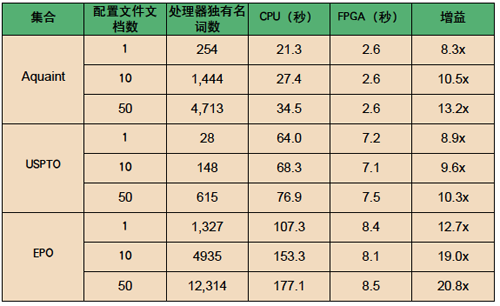
我们在表2和图5中对有关结果进行了总结。从表中可以清晰地看出,FPGA实施方案在速度方面通常比标准实施方案快一个数量级。从图中可以看出,配置文件大小(需要匹配的词数)增加后,标准实施方案变得越来越慢,而FPGA实施方案的速度相对保持不变。这是因为FPGA实施方案支持配置文件评分的流分线操作,这样无论配置文件大小如何,时延基本保持不变。这些结果清晰表明,FPGA对加速IR任务有着巨大的潜力。FPGA的提速幅度已然相当大(特别对大型配置文件而言尤其明显),而且仍有进一步提高的空间。通过仿真,我们确认FPGA算法给一个文档词评分需要两个时钟周期。制约因素为每周期128位的SRAM存取速度,这需要两个周期才能读取四个配置文件词。如果时钟速度为 100MHz,则意味着FPGA能在15秒之内完成整个EPO文档集合的评分。当前应用在四个FPGA上需要约8.5秒,因此原则上我们至少可以让性能再翻一番。
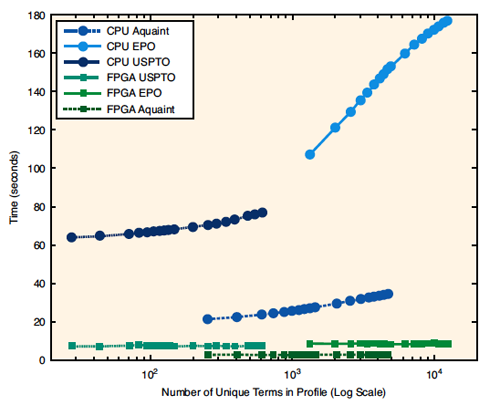
差异的原因在于I/O流 (streamingI/O):通过主机操作系统设备驱动器可将文档流从用户存储器空间传输至NUMAlink,这需要直接存储器存取(DMA)传输。驱动器可传输流的缓存模块。目前,对所传输模块的大小来说,这一传输并不是以最优的方式实施的,进而导致无法达到最高吞吐量。此外,用独立的线程进行传输排序也能避免传输时延。
遇到的问题和吸取的经验
这一项目的意义不仅在于它展示了FPGA作为信息检索任务加速器的优势,而且还为我们提供了FPGA加速系统软硬件要求的重要信息。
至主机系统的I/O是确保性能的关键:NUMA存储器与FPGA之间的DMA机制必须获得Mitrionics SDK和SGIRASClib的支持。在此前的项目中,我们必须先将数据传输到电路板上的SRAM中才能进行处理,但这会严重影响性能,因为数据的载入和结果的卸载会造成非常大的开销。此外,我们也清晰地认识到,IR任务尤其需要大量的片上和板上存储器,才能实现效率最大化。
此外,为了充分使用FPGA,未来的平台必须具备两个重要特性,一是必需能在FPGA之间直接传输数据,二是必需能够关闭主机处理器(或用一个主机处理器控制多个FPGA)。关闭主机处理器的功能尤其重要:在Altix平台上,即便Itanium处理器完全处于空闲状态也不能关闭。但是,空闲的Itanium处理器的功耗也高达工作状态下所需功耗的90%。因此,尽管FPGA加速的节能效果明显,但我们目前的系统即便在加速器运行过程中主机存储器空闲状态下,其总体节能作用仍然有限。
开发FPGA加速型系统的另一重要领域就是软件。我们的经验明确反映出,主要的复杂问题在于FPGA和主机系统之间的接口连接:Mitrion-C中的实际 FPGA应用开发效率非常高;采用Lemur工具套件构建查询和服务文档的框架也相对容易开发。但是,采用RASClib开发连接主机应用和FPGA接口的代码非常复杂,而且由于并发性问题,还非常难以调试。因而,接口代码的开发占据了绝大部分的开发时间。
FPGA高级编程的最后一个问题是编译速度。习惯于C++或Java等语言的开发人员认为即便应用非常复杂,构建时间也应该比较短。除了最基本的设计之外,当前的FPGA工具执行综合以及放置路由工作几乎都需要一整天的时间。非常长的构建时间会严重影响工作效率,因而时间应当缩短到一般性软件构建时间,这样才能使 FPGA 加速更具吸引力。
定制硬件平台
我们用这个项目探讨了FPGA加速的可能性,并展示了FPGA作为数据中心绿色环保技术的巨大潜力。我们希望进一步扩展这项研究,调查文档处理所需的全系列工作任务,如语法分析、词干、索引、搜索以及过滤等。我们清楚地认识到,现有系统在节能潜力方面很有限,我们希望研究能以业界最高效率专门执行信息检索任务的可定制硬件平台。这样,我们就能显著加速算法的执行,同时大幅度降低能耗,从而开发出更加环保、速度更快的数据中心。

本视频基于Xilinx公司的Artix-7FPGA器件以及各种丰富的入门和进阶外设,提供了一些典型的工程实例,帮助读者从FPGA基础知识、逻辑设计概念

本课程为“从零开始大战FPGA”系列课程的基础篇。课程通俗易懂、逻辑性强、示例丰富,课程中尤其强调在设计过程中对“时序”和“逻辑”的把控,以及硬件描述语言与硬件电路相对应的“

课程中首先会给大家讲解在企业中一般数字电路从算法到流片这整个过程中会涉及到哪些流程,都分别使用什么工具,以及其中每个流程都分别做了
@2003-2020 中国电子顶级开发网





