随着计算机技术的飞速发展,PCI总线已经远远不能满足当前处理器和I/O设备对带宽的更高需求。传统PCI和PCI-X[1]总线都是多点并行互连总线(即多台设备共享一条总线),并行总线之间存在相互干扰、时钟抖动,这些因素制约了其带宽。PCI-SIG(Peripheral Component Interconnect Special Interest Group)推出的第三代I/O系统PCIE(PCI-Express)[2]能够实现两台设备之间点对点的串行通信,使用交换器还可实现多台PCI-Express设备的互连,而且具有管脚少、带宽高、外围传播能力强、兼容性能好等特点。目前,PCI-Express 1.0a发送和接收的数据速率可达2.5 Gb/s。
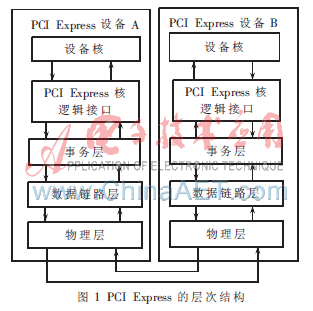
类似于OSI(Open System Interconnection)网络模型,PCI-Epxress引入了分层概念,层与层之间透明,各自完成独立功能的同时又紧密联系。PCIE总共分为三层:物理层、数据链路层和事务层。其层次结构[3]如图1所示。
物理层分为逻辑物理层和电气物理层。逻辑物理层完成对数据包的合成分解、8 b/10 b编码和10 b/9 b解码、并串转换和串并转换;电气物理层负责对每路串行数据差分驱动的传输与接收及阻抗匹配;数据链路层是其中间层,主要负责链路管理、与数据完整性相关的功能,包括错误检测和错误改正以及产生和处理数据链路层包。事务层是PCI Express架构的上层,其主要功能是接收、缓冲和分发事务包TLP(Transaction Layer Packet)。TLP通过使用存储器、I/O、配置和消息事务来传递信息。为了最大限度地提高器件之间的通信效率,事务层强制遵循符合PCIE的事务排序规则,并通过基于信用的流量控制来管理TLP缓冲空间。
在PCI-Express系统中,CPU由两种事务来访问其架构中的存储器映射输入输出和配置映射输入输出位置。一种是程控输入输出(Programmed Input Output)方式,该方式在数据传输的过程中需要CPU的直接参与,其速度较慢、效率较低;另一种是直接内存访问DMA(Direct Memory Access)方式,该方式在实现高速外设和主存储器之间成批交换数据时,不需要CPU的直接参与,而在RAM与设备之间完成传输时,该方式可减少CPU的占用率,大大提高了数据的吞吐率,使系统的性能大幅度提升。DMA方式有两种类型:第三方DMA(third-party DMA)和第一方DMA(first-party DMA)或称总线主控DMA(Bus-mastering DMA)。第三方DMA通过系统主板上的DMA控制器的仲裁来获得总线和传输数据。而第一方DMA则完全由接口卡上的逻辑电路来完成,与快取内存结合在一起,提高了数据的存取及传输性能。
Xilinx公司Virtex-5系列FPGA提供了PCIE的IP核[4-5],支持以上几种事务访问方式,在核中固化了物理层和数据链路层的相关设计,向用户开放事务层接口,在进行PCI-Express相关设计时,用户只需要配置相关参数来完成物理层和数据链路层的设计,从而只专注于事务层设计与开发,缩短了产品的研发周期。
本文采用总线主控DMA方式,完成了PCI Express数据事务层的接口设计。使用Verilog HDL语言编写,实现了处理器内存与用户逻辑之间数据的高效传输。
1 PCI-Express数据事务层DMA方式设计
1.1 设计结构
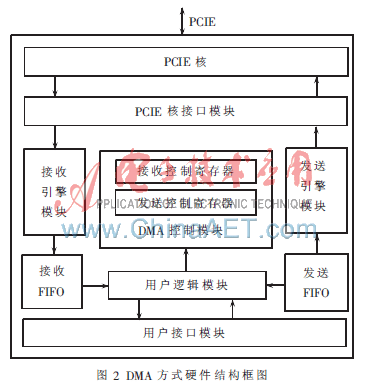
DMA方式硬件结构如图2所示,采用自顶向下设计方法[6-8],将FPGA内部逻辑划分为7个模块。
(1)PCIE核接口模块:该模块完成与Xinlinx PCIE核接口信号的对接及对PCIE核的初始化配置。
(2)发送引擎模块:该模块按照PCI-ExpressTM Base
Specification Revision 1.0a协议将待发送的数据和寄存器信息封装成事务包(TLP)传输到PCIE核接口模块。
(3)接收引擎模块:该模块按照协议将从PCIE核接口模块接收下来的事务包解封装,并根据TLPs的头标中的信息将数据分流,分别写入接收控制寄存器或是接收FIFO中。
(4)DMA控制模块:DMA控制寄存器由中断原因寄存器、接收控制寄存器和发送控制寄存器构成。中断原因寄存器中存放中断产生的原因。接收控制寄存器用来接收存放内存读请求MRd(Memory Read Request)操作的DMA控制信息,包括内存读请求地址寄存器、读长度寄存器、读包数寄存器、读完成包数寄存器。发送控制寄存器用来存储内存写请求MWR(Memory Write Request)的DMA控制信息,包括内存写请求地址寄存器、写长度寄存器和写包数寄存器。
(5)输入输出缓存模块:为了提高数据传输率、处理大量数据流、匹配具有不同传输率的系统以及缓存数据以备处理,利用了两个独立的FIFO数据通道。一个用于PCIE发送引擎模块到用户逻辑模块传输数据时的缓存(称为发送FIFO);另一个用于用户逻辑模块到PCIE接收引擎模块传输数据时的缓存(称为接收FIFO)。
(6)用户逻辑模块:配置和读取DMA控制寄存器及控制数据的输入输出。用户逻辑通过读取寄存器的值来控制中断和数据的传输。
(7)用户接口模块:提供用户简单的数据接口通道和控制信号,屏蔽复杂的控制操作并简化用户操作。
1.2 设计流程
1.2.1 DMA状态流程
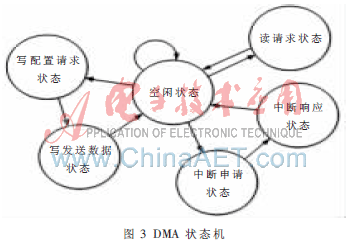
(1)DMA状态机如图3所示,由如下几个状态组成:
空闲状态:状态机无数据传输时默认保持在该状态,当写请求信号有效时,状态机转入写配置请求状态;当读请求信号有效时,状态机转入读请求状态;当满足中断触发条件时,状态机转入中断申请状态。
(2)写配置请求状态:通过该状态FPGA将本次传输发送的数据长度及TLPs包数等信息发送给处理器,为大规模的数据传输做好准备。
(3)写发送数据状态:控制完成FPGA和HOST内存之间的大规模数据传输。
(4)读请求状态:根据控制寄存器中的相关信息,发出数据的读请求事务。
(5)中断申请状态:当硬件发送和接收的数据传输完毕或是空闲等待时间满足一定触发条件时,状态机会在保存现场之后跳转到中断申请状态。该状态向处理器发出中断申请,同时根据产生中断的原因相应地置位中断原因寄存器。
(6)中断响应状态:当处理器响应中断后,硬件状态机同步转入中断完成状态,同时清空中断原因寄存器中相应的位,恢复中断前的现场环境。
1.2.2 存储器写传输流程
存储器写传输有两种情况:FPGA发送存储器写请求至HOST内存和HOST内存发送存储器写请求至FPGA,即FPGA接收存储器的写请求。
FPGA发送存储器写请求TLPs流程如图4(a)所示。首先,用户接口模块将待发送的数据依次传送到发送FIFO中,同时通过用户逻辑模块在发送控制寄存器中配置该次传输的信息,包括存储器写请求的目的地址、本次传输数据的长度和本次传输的总TLPs包数。其次,当发送FIFO中待发送的数据准备就绪时,开始发送FIFO中数据。当用户接口模块待发送数据全部传输完毕之后,FPGA发出中断请求通知处理器传输完毕,处理器响应中断后,一次完整的存储器写请求事务结束。
只要FPGA的接收FIFO中数据未溢出,即可接收HOST内存的MWr TLPs。接收引擎模块根据接收到的TLP头表中类型和格式字段的编码判断其类型,按照协议规定的格式解开其封装,发送数据到接收FIFO中,进而传送到用户接口模块。整个传输流程如图4(b)所示。
1.2.3 存储器读/完成传输流程
存储器读/完成传输有两种情况:FPGA发送存储器读请求和接收带数据的完成返回包CPLD(Completion with Data);FPGA接收存储器读请求和发送带数据的完成返回包。
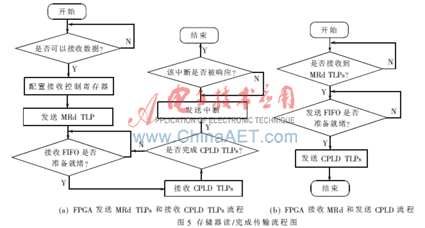
FPGA发送存储器读请求MRd TLPs和接收CPLD TLPs流程如图5(a)所示,只要接收FIFO没有溢出,FPGA即可发起存储器读事务。每次发出MRd请求之前,需要通过用户逻辑模块在接收控制寄存器中配置该次传输需要读取的信息,包括内存读请求的源地址、本次接收数据的长度和本次接收的总TLPs包数。HOST内存从MRd头信息中获知本次事务要读取设备存储空间的地址和长度,并根据此发送CPLD到FPGA。接收引擎模块根据协议包格式在CPLD中提取出承载的数据,并将数据传送到用户接口模块。当请求的数据全部接收完毕之后,FPGA发出中断请求通知处理器传输完毕,处理器响应中断后,一次完整的存储器读请求事务结束。
当FPGA接收MRd和发送CPLD TLP时,接收引擎模块根据接收到的MRd携带的信息,从存储空间中读取数据到发送FIFO中,当发送FIFO中的数据准备就绪后,FPGA开始发送CPLD,直到全部被读取的数据都发送完毕后,结束本次数据传输。整个传输流程如图5(b)所示。
2 硬件验证
本文使用Verilog HDL语言编写代码输入、代码调试、功能仿真、综合、布局布线后,再进行仿真、时序分析和验证,最后下载到Xilinx公司的XCVSX50T芯片中,使用ChipScope对设计进行硬件分析和验证。采用联想天启M430E电脑搭建测试环境,在Windows XP系统下编写测试代码对PCI Express接口数据传输的速率进行测试。测试过程分为两个步骤:(1)对该设计功能的正确性进行验证;(2)对该设计的传输性能进行测试与分析。
2.1 功能验证
首先对FPGA发送MWr事务进行验证。设定每个TLP负载定长为32个长字,配置FPGA用户接口模块每次发送100 TLPs,总共要发送12 800 B数据。用ChipScope截取TLPs的时序如图6所示。其次对FPGA发送MRd,接收CPLD事务进行验证,配置FPGA用户接口模块从HOST内存中每次读取100 TLPs,每个TLP的负载定长为32个长字,FPGA共要接收12 800 B数据。用ChipScope截取TLPs的时序如图7所示。
通过对图6、图7的时序分析表明,该设计能够实现PCI-Express事务层功能,可以正常进行事务层上的会话,满足PCI-ExpressTM Base Specification Revision 1.0a协议,证明了本设计功能的可读性和可靠性。
2.2 性能分析
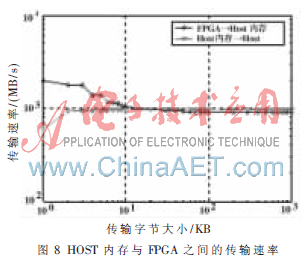
测试中PCI-Express采用了X4通道,每个通道最大传输速率为2.5 Gb/s,理论最大的带宽可以达到10 Gb/s,但由于PCI-Express采用了8 b/10 b编码,所以实际传输的有效带宽为8 Gb/s。图8为HOST内存与FPGA之间的传输速率,实际测试中,FPGA传输数据到HOST内存的速率稳定后达到0.9 GB/s(7.2 Gb/s),达到理论带宽的90%;HOST内存传输数据到FPGA的速率稳定后达到0.96 GB/s(7.6 Gb/s),达到理论带宽的96%。
综上可以看出,本文的设计有效减少了数据传输过程中的等待时间,大幅度地提高了数据传输速率,充分发挥了PCI Express总线的优越性能。
参考文献
[1] PCI Special Interest Group PCI local bus specification 2.3[S]. 2002.
[2] PCI Special Interest Group.PCI-ExpressTM base specification Revision 1.0a base[S]. 2003.
[3] BUDRUD R, ANDERSON D, SHANLEY T. PCI express system architecture[M]. MindShare, Inc, 2003.
[4] XILINX Inc. Virtex-5 Integrated Endpoint Block for PCI Express Designs[R]. 2009.
[5] XILINX Inc. LogiCORE? IP endpoint block plus v1.14 for PCI Express[R]. 2010.
[6] 夏宇闻. Verilog数字系统设计教程[M]. 北京: 北京航空航天大学出版社, 2008.
[7] HALL S H, HALL G W, MCCALL J A. High-speed digital system design a handbook of interconnect theory and design practices[M].北京:机械工业出版社,2000.
[8] JOHNSON H, GRAHAM M. High-speed digital design: a handbook of black magic[M]. 北京: 电子工业出版社,2010.
[9] HYUN E, Seng Kwangsu. Design and verification for PCI express controller[C]. ICITA'05, 2005:581-586.
[10] 马鸣锦,朱剑冰,何红旗,等. PCI、PCI-X和PCI Express的原理及体系结构[M]. 北京: 清华大学出版社,2007.

本视频基于Xilinx公司的Artix-7FPGA器件以及各种丰富的入门和进阶外设,提供了一些典型的工程实例,帮助读者从FPGA基础知识、逻辑设计概念

本课程为“从零开始大战FPGA”系列课程的基础篇。课程通俗易懂、逻辑性强、示例丰富,课程中尤其强调在设计过程中对“时序”和“逻辑”的把控,以及硬件描述语言与硬件电路相对应的“

课程中首先会给大家讲解在企业中一般数字电路从算法到流片这整个过程中会涉及到哪些流程,都分别使用什么工具,以及其中每个流程都分别做了
@2003-2020 中国电子顶级开发网